






Deepseek - What To Do When Rejected
페이지 정보
작성자 Loretta Gibbs 작성일25-02-01 17:21 조회14회 댓글0건본문
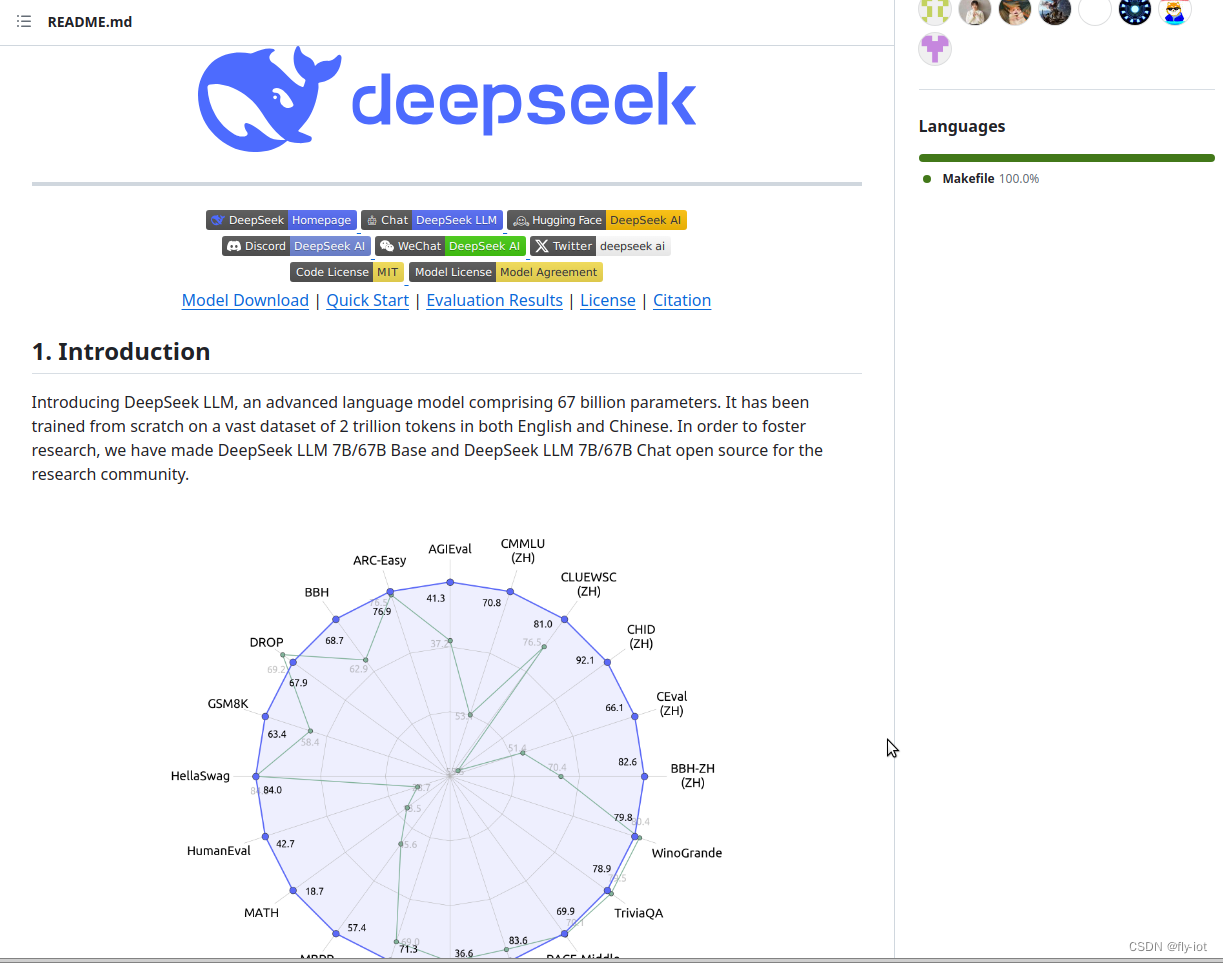
By open-sourcing its fashions, code, and data, DeepSeek LLM hopes to promote widespread AI research and business functions. It will possibly have necessary implications for purposes that require searching over an enormous space of attainable options and have tools to confirm the validity of mannequin responses. "More exactly, our ancestors have chosen an ecological niche the place the world is gradual sufficient to make survival attainable. Crafter: A Minecraft-impressed grid atmosphere where the participant has to explore, gather resources and craft objects to ensure their survival. Compared, our sensory systems collect information at an unlimited fee, no less than 1 gigabits/s," they write. To get a visceral sense of this, take a look at this post by AI researcher Andrew Critch which argues (convincingly, imo) that numerous the danger of Ai programs comes from the fact they may think lots sooner than us. Then these AI systems are going to have the ability to arbitrarily access these representations and bring them to life. One necessary step towards that's exhibiting that we will be taught to represent difficult games after which carry them to life from a neural substrate, which is what the authors have executed right here.
 To help the research group, we have now open-sourced deepseek ai china-R1-Zero, DeepSeek-R1, and 6 dense models distilled from DeepSeek-R1 based on Llama and Qwen. Note: The full dimension of DeepSeek-V3 models on HuggingFace is 685B, which incorporates 671B of the primary Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. Note: Huggingface's Transformers has not been straight supported but. In the next installment, we'll build an utility from the code snippets within the previous installments. The code is publicly accessible, permitting anybody to use, examine, modify, and build upon it. DeepSeek Coder comprises a sequence of code language fashions educated from scratch on both 87% code and 13% pure language in English and Chinese, with each mannequin pre-educated on 2T tokens. "GameNGen solutions one of the necessary questions on the highway in direction of a new paradigm for game engines, one the place video games are mechanically generated, equally to how photographs and videos are generated by neural models in latest years".
To help the research group, we have now open-sourced deepseek ai china-R1-Zero, DeepSeek-R1, and 6 dense models distilled from DeepSeek-R1 based on Llama and Qwen. Note: The full dimension of DeepSeek-V3 models on HuggingFace is 685B, which incorporates 671B of the primary Model weights and 14B of the Multi-Token Prediction (MTP) Module weights. Note: Huggingface's Transformers has not been straight supported but. In the next installment, we'll build an utility from the code snippets within the previous installments. The code is publicly accessible, permitting anybody to use, examine, modify, and build upon it. DeepSeek Coder comprises a sequence of code language fashions educated from scratch on both 87% code and 13% pure language in English and Chinese, with each mannequin pre-educated on 2T tokens. "GameNGen solutions one of the necessary questions on the highway in direction of a new paradigm for game engines, one the place video games are mechanically generated, equally to how photographs and videos are generated by neural models in latest years".
What they did specifically: "GameNGen is trained in two phases: (1) an RL-agent learns to play the sport and the training periods are recorded, and (2) a diffusion model is skilled to supply the following frame, conditioned on the sequence of past frames and actions," Google writes. "I drew my line somewhere between detection and tracking," he writes. Why this matters on the whole: "By breaking down obstacles of centralized compute and lowering inter-GPU communication requirements, DisTrO might open up alternatives for widespread participation and collaboration on international AI initiatives," Nous writes. AI startup Nous Research has revealed a really brief preliminary paper on Distributed Training Over-the-Internet (DisTro), a technique that "reduces inter-GPU communication necessities for each coaching setup without using amortization, enabling low latency, environment friendly and no-compromise pre-coaching of giant neural networks over shopper-grade internet connections using heterogenous networking hardware". The paper presents a new massive language mannequin called DeepSeekMath 7B that's specifically designed to excel at mathematical reasoning. The model goes head-to-head with and sometimes outperforms fashions like GPT-4o and Claude-3.5-Sonnet in varied benchmarks. Why this matters - scale might be crucial factor: "Our fashions demonstrate robust generalization capabilities on a wide range of human-centric tasks.
 Why are people so rattling gradual? Non-reasoning data was generated by DeepSeek-V2.5 and checked by humans. The Sapiens fashions are good because of scale - specifically, lots of knowledge and many annotations. The LLM 67B Chat model achieved a formidable 73.78% go fee on the HumanEval coding benchmark, surpassing models of related measurement. HumanEval Python: DeepSeek-V2.5 scored 89, reflecting its vital developments in coding talents. Accessibility and licensing: DeepSeek-V2.5 is designed to be extensively accessible whereas maintaining certain ethical requirements. While the mannequin has an enormous 671 billion parameters, it solely uses 37 billion at a time, making it extremely efficient. As an illustration, retail corporations can predict buyer demand to optimize inventory levels, while monetary establishments can forecast market trends to make informed investment decisions. Why this issues - constraints force creativity and creativity correlates to intelligence: You see this sample over and over - create a neural internet with a capability to be taught, give it a process, then be sure you give it some constraints - right here, crappy egocentric vision.
Why are people so rattling gradual? Non-reasoning data was generated by DeepSeek-V2.5 and checked by humans. The Sapiens fashions are good because of scale - specifically, lots of knowledge and many annotations. The LLM 67B Chat model achieved a formidable 73.78% go fee on the HumanEval coding benchmark, surpassing models of related measurement. HumanEval Python: DeepSeek-V2.5 scored 89, reflecting its vital developments in coding talents. Accessibility and licensing: DeepSeek-V2.5 is designed to be extensively accessible whereas maintaining certain ethical requirements. While the mannequin has an enormous 671 billion parameters, it solely uses 37 billion at a time, making it extremely efficient. As an illustration, retail corporations can predict buyer demand to optimize inventory levels, while monetary establishments can forecast market trends to make informed investment decisions. Why this issues - constraints force creativity and creativity correlates to intelligence: You see this sample over and over - create a neural internet with a capability to be taught, give it a process, then be sure you give it some constraints - right here, crappy egocentric vision.
If you have any issues regarding exactly where and how to use ديب سيك, you can call us at our web page.
댓글목록
등록된 댓글이 없습니다.


