






The Evolution Of Deepseek
페이지 정보
작성자 Georgianna 작성일25-02-01 08:39 조회10회 댓글0건본문
 Later, on November 29, 2023, DeepSeek launched DeepSeek LLM, described because the "next frontier of open-supply LLMs," scaled up to 67B parameters. 610 opened Jan 29, 2025 by Imadnajam Loading… Habeshian, Sareen (28 January 2025). "Johnson bashes China on AI, Trump calls DeepSeek improvement "positive"". Sharma, Manoj (6 January 2025). "Musk dismisses, Altman applauds: What leaders say on DeepSeek's disruption". In January 2024, this resulted in the creation of more advanced and environment friendly models like DeepSeekMoE, which featured a sophisticated Mixture-of-Experts architecture, and a brand new model of their Coder, DeepSeek-Coder-v1.5. This new release, issued September 6, 2024, combines both normal language processing and coding functionalities into one powerful mannequin. Since May 2024, now we have been witnessing the event and success of DeepSeek-V2 and DeepSeek-Coder-V2 fashions. By nature, the broad accessibility of latest open supply AI fashions and permissiveness of their licensing means it is easier for other enterprising developers to take them and enhance upon them than with proprietary fashions. As companies and builders search to leverage AI more effectively, DeepSeek-AI’s newest launch positions itself as a top contender in both general-purpose language tasks and specialised coding functionalities. Base Models: 7 billion parameters and 67 billion parameters, focusing on normal language tasks.
Later, on November 29, 2023, DeepSeek launched DeepSeek LLM, described because the "next frontier of open-supply LLMs," scaled up to 67B parameters. 610 opened Jan 29, 2025 by Imadnajam Loading… Habeshian, Sareen (28 January 2025). "Johnson bashes China on AI, Trump calls DeepSeek improvement "positive"". Sharma, Manoj (6 January 2025). "Musk dismisses, Altman applauds: What leaders say on DeepSeek's disruption". In January 2024, this resulted in the creation of more advanced and environment friendly models like DeepSeekMoE, which featured a sophisticated Mixture-of-Experts architecture, and a brand new model of their Coder, DeepSeek-Coder-v1.5. This new release, issued September 6, 2024, combines both normal language processing and coding functionalities into one powerful mannequin. Since May 2024, now we have been witnessing the event and success of DeepSeek-V2 and DeepSeek-Coder-V2 fashions. By nature, the broad accessibility of latest open supply AI fashions and permissiveness of their licensing means it is easier for other enterprising developers to take them and enhance upon them than with proprietary fashions. As companies and builders search to leverage AI more effectively, DeepSeek-AI’s newest launch positions itself as a top contender in both general-purpose language tasks and specialised coding functionalities. Base Models: 7 billion parameters and 67 billion parameters, focusing on normal language tasks.
 It’s notoriously difficult as a result of there’s no common formulation to use; solving it requires creative thinking to take advantage of the problem’s construction. Data is definitely at the core of it now that LLaMA and Mistral - it’s like a GPU donation to the general public. Smaller, specialized fashions educated on high-high quality data can outperform bigger, general-function models on specific duties. The open-source world, so far, has more been concerning the "GPU poors." So in the event you don’t have lots of GPUs, however you continue to need to get business value from AI, how can you try this? I believe it’s extra like sound engineering and plenty of it compounding together. ✨ As V2 closes, it’s not the top-it’s the start of one thing larger. On November 2, 2023, DeepSeek started rapidly unveiling its fashions, beginning with DeepSeek Coder. How can I get help or ask questions about DeepSeek Coder? This can be a non-stream instance, you can set the stream parameter to true to get stream response. Have you set up agentic workflows? The reward for DeepSeek-V2.5 follows a nonetheless ongoing controversy round HyperWrite’s Reflection 70B, which co-founder and CEO Matt Shumer claimed on September 5 was the "the world’s prime open-supply AI model," according to his internal benchmarks, solely to see these claims challenged by independent researchers and the wider AI research group, who've to date didn't reproduce the said outcomes.
It’s notoriously difficult as a result of there’s no common formulation to use; solving it requires creative thinking to take advantage of the problem’s construction. Data is definitely at the core of it now that LLaMA and Mistral - it’s like a GPU donation to the general public. Smaller, specialized fashions educated on high-high quality data can outperform bigger, general-function models on specific duties. The open-source world, so far, has more been concerning the "GPU poors." So in the event you don’t have lots of GPUs, however you continue to need to get business value from AI, how can you try this? I believe it’s extra like sound engineering and plenty of it compounding together. ✨ As V2 closes, it’s not the top-it’s the start of one thing larger. On November 2, 2023, DeepSeek started rapidly unveiling its fashions, beginning with DeepSeek Coder. How can I get help or ask questions about DeepSeek Coder? This can be a non-stream instance, you can set the stream parameter to true to get stream response. Have you set up agentic workflows? The reward for DeepSeek-V2.5 follows a nonetheless ongoing controversy round HyperWrite’s Reflection 70B, which co-founder and CEO Matt Shumer claimed on September 5 was the "the world’s prime open-supply AI model," according to his internal benchmarks, solely to see these claims challenged by independent researchers and the wider AI research group, who've to date didn't reproduce the said outcomes.
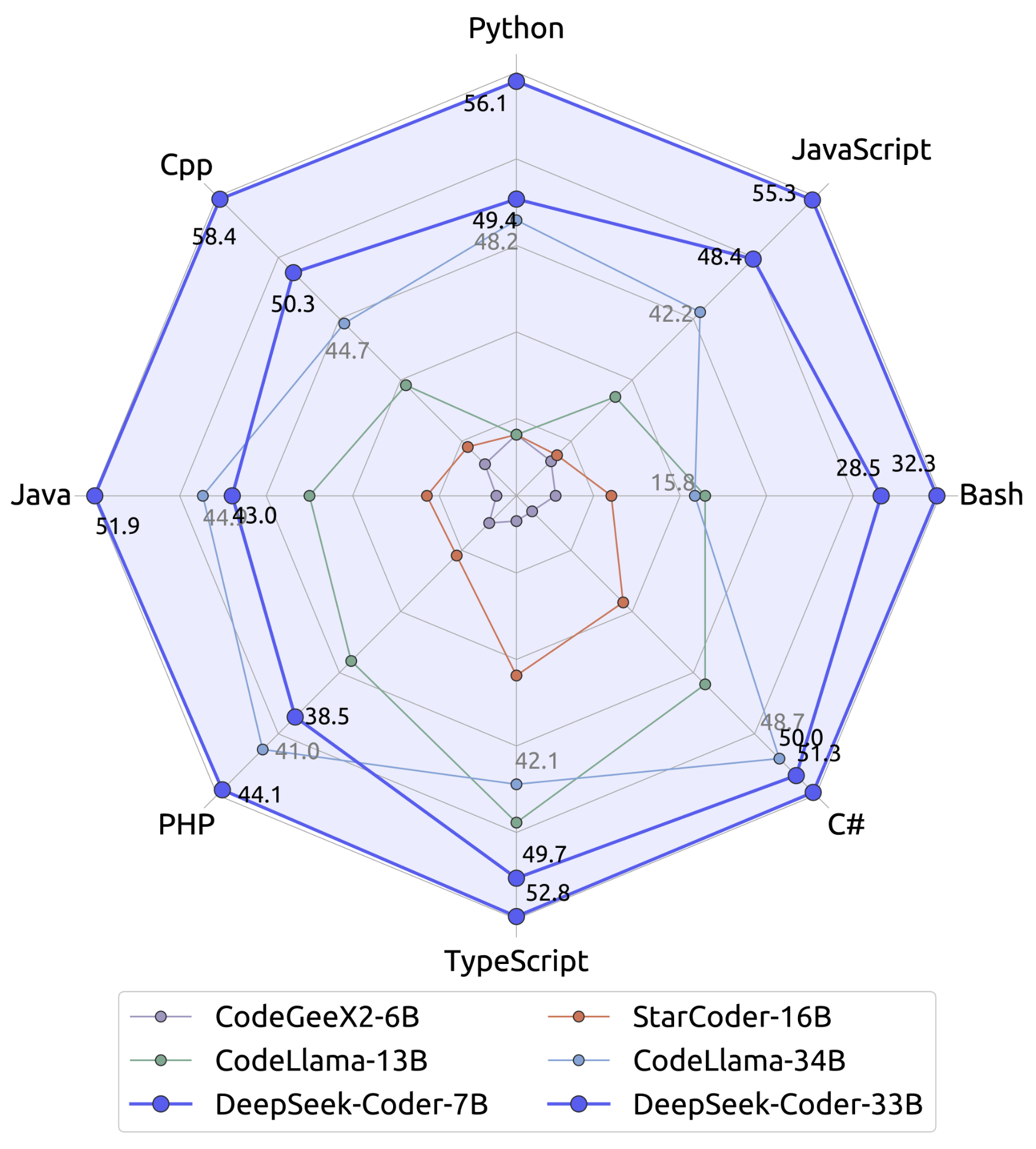
HumanEval Python: DeepSeek-V2.5 scored 89, reflecting its vital advancements in coding talents. DeepSeek-V2.5 excels in a variety of essential benchmarks, demonstrating its superiority in both pure language processing (NLP) and coding duties. DeepSeek-V2.5 is optimized for several tasks, including writing, instruction-following, and superior ديب سيك coding. By making DeepSeek-V2.5 open-source, DeepSeek-AI continues to advance the accessibility and potential of AI, cementing its function as a frontrunner in the sector of massive-scale fashions. Initially, DeepSeek created their first model with architecture much like different open models like LLaMA, aiming to outperform benchmarks. This smaller model approached the mathematical reasoning capabilities of GPT-four and outperformed one other Chinese mannequin, Qwen-72B. DeepSeek LLM 67B Chat had already demonstrated significant performance, approaching that of GPT-4. As we've already noted, DeepSeek LLM was developed to compete with different LLMs available on the time. Open-sourcing the new LLM for public research, DeepSeek AI proved that their DeepSeek Chat is significantly better than Meta’s Llama 2-70B in numerous fields.
With an emphasis on better alignment with human preferences, it has undergone numerous refinements to make sure it outperforms its predecessors in nearly all benchmarks. In further checks, it comes a distant second to GPT4 on the LeetCode, Hungarian Exam, and IFEval exams (although does better than quite a lot of different Chinese fashions). This is exemplified in their DeepSeek-V2 and DeepSeek-Coder-V2 models, with the latter extensively regarded as one of the strongest open-source code fashions out there. The sequence includes eight models, 4 pretrained (Base) and 4 instruction-finetuned (Instruct). The Chat versions of the 2 Base models was also launched concurrently, obtained by coaching Base by supervised finetuning (SFT) followed by direct coverage optimization (DPO). In solely two months, DeepSeek came up with something new and attention-grabbing. While much attention within the AI community has been focused on fashions like LLaMA and Mistral, DeepSeek has emerged as a major participant that deserves closer examination. AI is a power-hungry and cost-intensive technology - a lot in order that America’s most highly effective tech leaders are buying up nuclear energy firms to provide the required electricity for his or her AI fashions. Let’s explore the specific fashions in the DeepSeek family and how they manage to do all of the above.
For those who have almost any inquiries about wherever in addition to tips on how to employ ديب سيك مجانا, you'll be able to email us in our web-page.
댓글목록
등록된 댓글이 없습니다.


