






Deepseek Hopes and Dreams
페이지 정보
작성자 Armand 작성일25-01-31 23:31 조회11회 댓글0건본문
The DeepSeek chatbot defaults to utilizing the DeepSeek-V3 mannequin, however you can change to its R1 mannequin at any time, by merely clicking, or tapping, the 'DeepThink (R1)' button beneath the prompt bar. The freshest model, launched by DeepSeek in August 2024, is an optimized version of their open-source model for theorem proving in Lean 4, DeepSeek-Prover-V1.5. To facilitate the efficient execution of our mannequin, deepseek we provide a dedicated vllm answer that optimizes efficiency for running our model effectively. The paper presents a brand new large language mannequin known as DeepSeekMath 7B that's specifically designed to excel at mathematical reasoning. The paper attributes the strong mathematical reasoning capabilities of DeepSeekMath 7B to two key components: the extensive math-associated data used for pre-training and the introduction of the GRPO optimization technique. The important thing innovation in this work is the usage of a novel optimization technique called Group Relative Policy Optimization (GRPO), which is a variant of the Proximal Policy Optimization (PPO) algorithm. Second, the researchers launched a new optimization technique referred to as Group Relative Policy Optimization (GRPO), which is a variant of the properly-known Proximal Policy Optimization (PPO) algorithm. The paper attributes the mannequin's mathematical reasoning abilities to two key components: leveraging publicly available web data and introducing a novel optimization approach known as Group Relative Policy Optimization (GRPO).
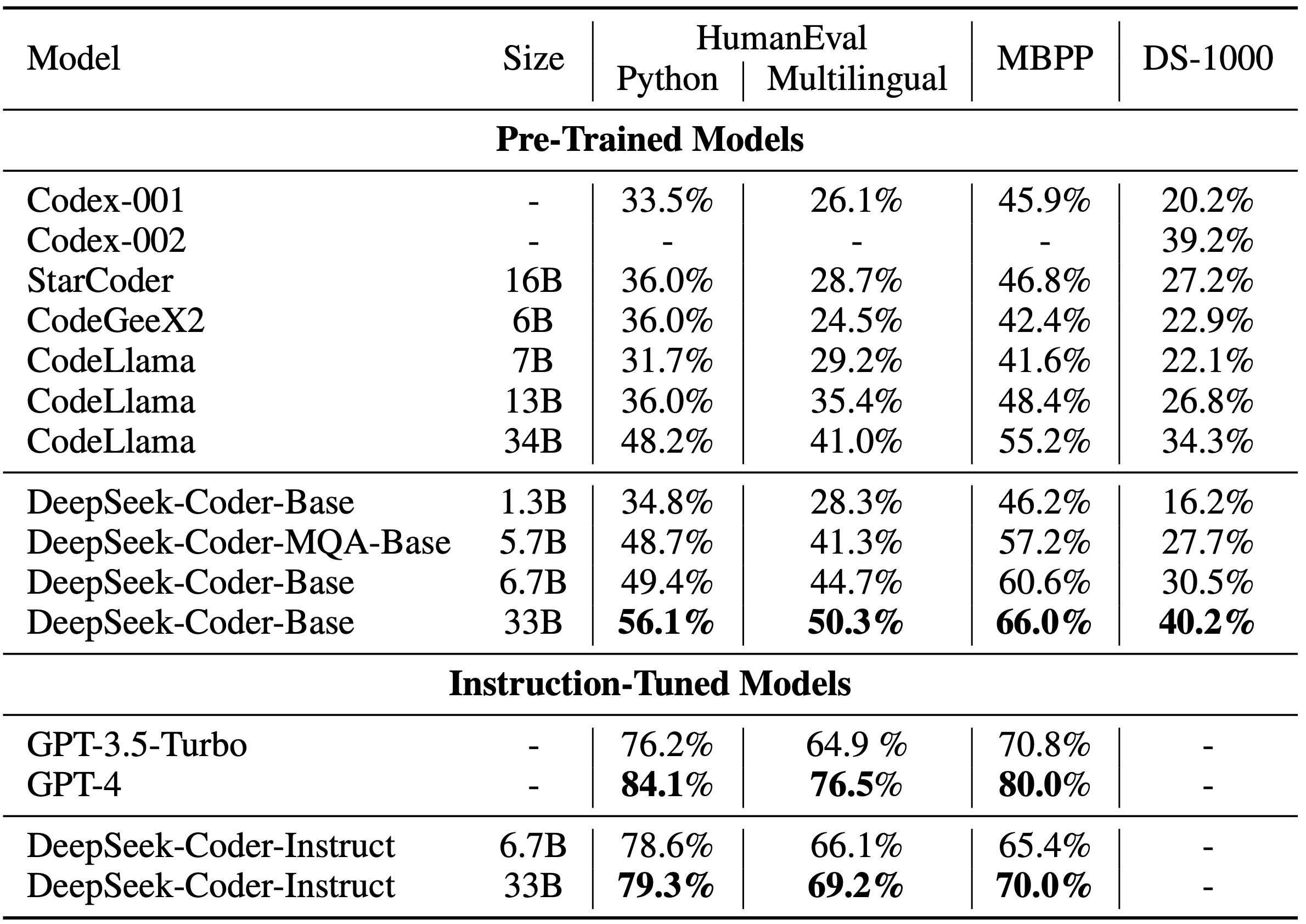 It is a Plain English Papers abstract of a analysis paper called DeepSeekMath: Pushing the limits of Mathematical Reasoning in Open Language Models. 1 spot on Apple’s App Store, pushing OpenAI’s chatbot apart. Each model is pre-educated on repo-degree code corpus by using a window measurement of 16K and a extra fill-in-the-clean activity, resulting in foundational fashions (DeepSeek-Coder-Base). The paper introduces DeepSeekMath 7B, a large language model that has been pre-educated on a large amount of math-associated data from Common Crawl, totaling a hundred and twenty billion tokens. First, they gathered a large amount of math-associated data from the online, including 120B math-related tokens from Common Crawl. The paper introduces DeepSeekMath 7B, a large language model trained on an unlimited quantity of math-related information to enhance its mathematical reasoning capabilities. Available now on Hugging Face, the mannequin gives customers seamless entry by way of web and API, and it appears to be the most superior large language model (LLMs) presently obtainable in the open-source panorama, in response to observations and assessments from third-occasion researchers. This knowledge, combined with natural language and code knowledge, is used to continue the pre-training of the DeepSeek-Coder-Base-v1.5 7B mannequin.
It is a Plain English Papers abstract of a analysis paper called DeepSeekMath: Pushing the limits of Mathematical Reasoning in Open Language Models. 1 spot on Apple’s App Store, pushing OpenAI’s chatbot apart. Each model is pre-educated on repo-degree code corpus by using a window measurement of 16K and a extra fill-in-the-clean activity, resulting in foundational fashions (DeepSeek-Coder-Base). The paper introduces DeepSeekMath 7B, a large language model that has been pre-educated on a large amount of math-associated data from Common Crawl, totaling a hundred and twenty billion tokens. First, they gathered a large amount of math-associated data from the online, including 120B math-related tokens from Common Crawl. The paper introduces DeepSeekMath 7B, a large language model trained on an unlimited quantity of math-related information to enhance its mathematical reasoning capabilities. Available now on Hugging Face, the mannequin gives customers seamless entry by way of web and API, and it appears to be the most superior large language model (LLMs) presently obtainable in the open-source panorama, in response to observations and assessments from third-occasion researchers. This knowledge, combined with natural language and code knowledge, is used to continue the pre-training of the DeepSeek-Coder-Base-v1.5 7B mannequin.
When mixed with the code that you just finally commit, it can be utilized to improve the LLM that you or your workforce use (when you enable). The reproducible code for the next analysis results will be discovered within the Evaluation directory. By following these steps, you possibly can easily combine multiple OpenAI-suitable APIs together with your Open WebUI occasion, unlocking the full potential of those highly effective AI models. With the flexibility to seamlessly combine multiple APIs, including OpenAI, Groq Cloud, and Cloudflare Workers AI, I have been capable of unlock the total potential of these highly effective AI fashions. The main benefit of using Cloudflare Workers over one thing like GroqCloud is their large number of models. Using Open WebUI via Cloudflare Workers isn't natively doable, however I developed my own OpenAI-compatible API for Cloudflare Workers just a few months ago. He actually had a weblog put up possibly about two months ago referred to as, "What I Wish Someone Had Told Me," which is probably the closest you’ll ever get to an sincere, direct reflection from Sam on how he thinks about building OpenAI.
OpenAI can either be considered the traditional or the monopoly. 14k requests per day is quite a bit, and 12k tokens per minute is considerably increased than the common particular person can use on an interface like Open WebUI. That is how I was in a position to use and evaluate Llama three as my replacement for ChatGPT! They even help Llama 3 8B! Here’s one other favorite of mine that I now use even more than OpenAI! Much more impressively, they’ve carried out this entirely in simulation then transferred the brokers to actual world robots who are able to play 1v1 soccer against eachother. Alessio Fanelli: I was going to say, Jordan, another method to give it some thought, just by way of open source and not as related but to the AI world where some international locations, and even China in a manner, had been perhaps our place is not to be at the leading edge of this. Although Llama 3 70B (and even the smaller 8B model) is ok for 99% of individuals and tasks, typically you just want the most effective, so I like having the choice either to only shortly reply my query and even use it along aspect different LLMs to quickly get choices for an answer.
If you adored this short article and you would such as to obtain additional details concerning ديب سيك kindly check out the page.
댓글목록
등록된 댓글이 없습니다.


