






Nine Surprisingly Effective Ways To Deepseek
페이지 정보
작성자 Tonia Upton 작성일25-02-01 07:05 조회5회 댓글0건본문
 In the open-weight category, I feel MOEs have been first popularised at the top of last year with Mistral’s Mixtral model and then extra not too long ago with DeepSeek v2 and v3. 2024 has additionally been the 12 months the place we see Mixture-of-Experts models come back into the mainstream again, significantly as a result of rumor that the unique GPT-four was 8x220B experts. In checks, the method works on some relatively small LLMs but loses power as you scale up (with GPT-four being harder for it to jailbreak than GPT-3.5). For both benchmarks, We adopted a greedy search strategy and re-applied the baseline outcomes utilizing the same script and setting for fair comparison. We fine-tune GPT-3 on our labeler demonstrations utilizing supervised learning. If you are a ChatGPT Plus subscriber then there are a variety of LLMs you'll be able to select when utilizing ChatGPT. On the TruthfulQA benchmark, InstructGPT generates truthful and informative solutions about twice as often as GPT-three During RLHF fine-tuning, we observe performance regressions in comparison with GPT-three We are able to greatly reduce the efficiency regressions on these datasets by mixing PPO updates with updates that enhance the log probability of the pretraining distribution (PPO-ptx), without compromising labeler choice scores.
In the open-weight category, I feel MOEs have been first popularised at the top of last year with Mistral’s Mixtral model and then extra not too long ago with DeepSeek v2 and v3. 2024 has additionally been the 12 months the place we see Mixture-of-Experts models come back into the mainstream again, significantly as a result of rumor that the unique GPT-four was 8x220B experts. In checks, the method works on some relatively small LLMs but loses power as you scale up (with GPT-four being harder for it to jailbreak than GPT-3.5). For both benchmarks, We adopted a greedy search strategy and re-applied the baseline outcomes utilizing the same script and setting for fair comparison. We fine-tune GPT-3 on our labeler demonstrations utilizing supervised learning. If you are a ChatGPT Plus subscriber then there are a variety of LLMs you'll be able to select when utilizing ChatGPT. On the TruthfulQA benchmark, InstructGPT generates truthful and informative solutions about twice as often as GPT-three During RLHF fine-tuning, we observe performance regressions in comparison with GPT-three We are able to greatly reduce the efficiency regressions on these datasets by mixing PPO updates with updates that enhance the log probability of the pretraining distribution (PPO-ptx), without compromising labeler choice scores.
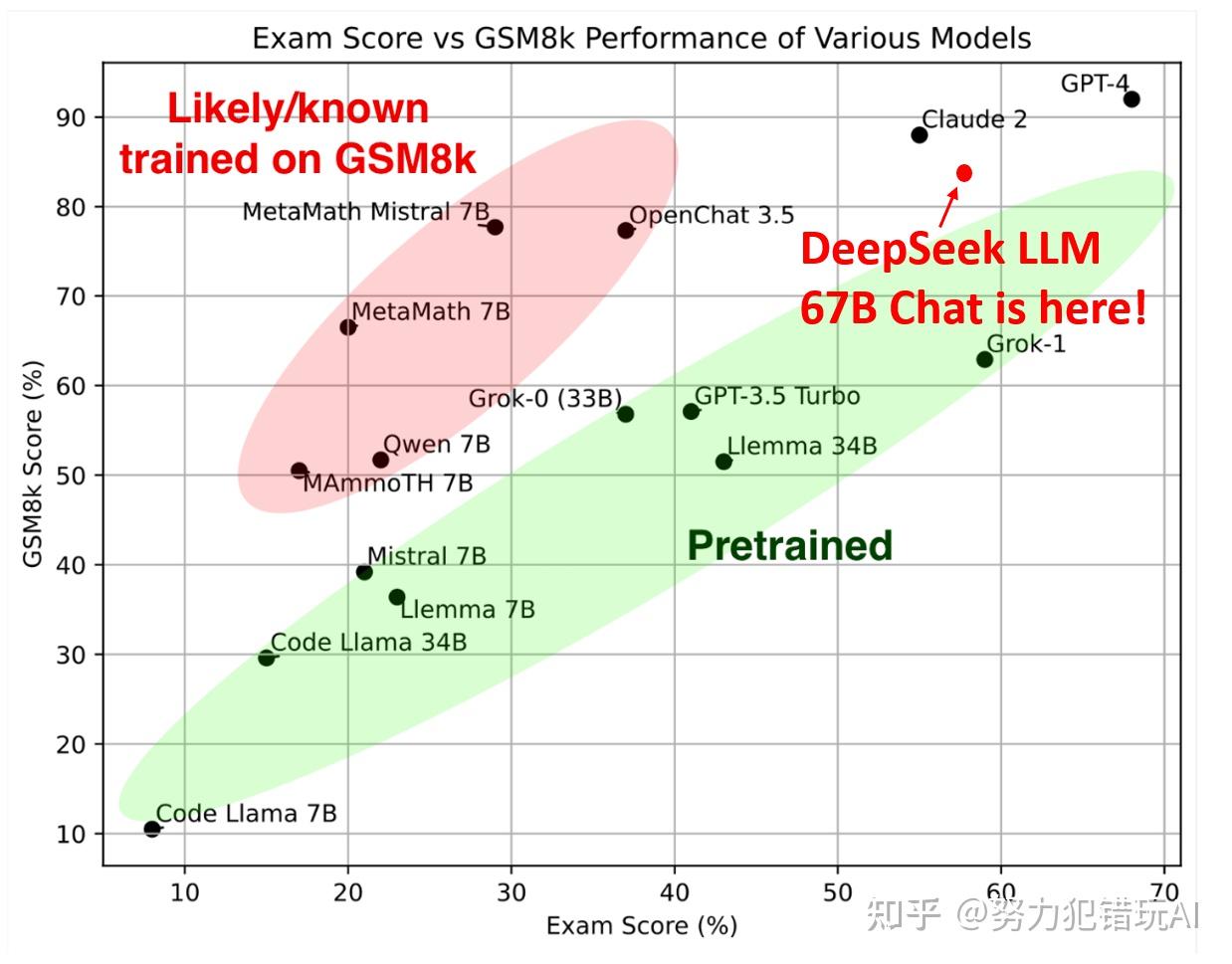
Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance in comparison with GPT-3.5. Besides, we try to organize the pretraining information on the repository stage to enhance the pre-skilled model’s understanding capability within the context of cross-recordsdata inside a repository They do that, by doing a topological type on the dependent information and appending them into the context window of the LLM. "include" in C. A topological type algorithm for doing this is offered within the paper. Curiosity and the mindset of being curious and making an attempt quite a lot of stuff is neither evenly distributed or generally nurtured. A lot of the trick with AI is determining the best approach to prepare this stuff so that you've a job which is doable (e.g, playing soccer) which is at the goldilocks degree of issue - sufficiently troublesome that you must provide you with some good issues to succeed in any respect, however sufficiently simple that it’s not unattainable to make progress from a chilly begin. The report, whose full title is the International Scientific Report on the Safety of Advanced AI, flags AI’s "rapidly growing" impression on the setting by the use of datacentres, and the potential for AI brokers to have a "profound" affect on the job market.
Both ChatGPT and free deepseek allow you to click to view the source of a selected advice, however, ChatGPT does a greater job of organizing all its sources to make them simpler to reference, and once you click on one it opens the Citations sidebar for easy accessibility. Compared to Meta’s Llama3.1 (405 billion parameters used abruptly), DeepSeek V3 is over 10 occasions extra environment friendly but performs better. That’s around 1.6 instances the scale of Llama 3.1 405B, which has 405 billion parameters. Hence, after k consideration layers, data can move forward by up to ok × W tokens SWA exploits the stacked layers of a transformer to attend data beyond the window size W . At every consideration layer, information can transfer forward by W tokens. No proprietary knowledge or deepseek coaching tips have been utilized: Mistral 7B - Instruct mannequin is a simple and preliminary demonstration that the base model can simply be wonderful-tuned to achieve good performance.
You can also use the mannequin to mechanically task the robots to collect information, which is most of what Google did here. We first rent a crew of 40 contractors to label our information, primarily based on their performance on a screening tes We then acquire a dataset of human-written demonstrations of the specified output behavior on (largely English) prompts submitted to the OpenAI API3 and a few labeler-written prompts, and use this to practice our supervised learning baselines. Next, we gather a dataset of human-labeled comparisons between outputs from our fashions on a larger set of API prompts. Our analysis indicates that the implementation of Chain-of-Thought (CoT) prompting notably enhances the capabilities of DeepSeek-Coder-Instruct fashions. 1. The base models were initialized from corresponding intermediate checkpoints after pretraining on 4.2T tokens (not the model at the top of pretraining), then pretrained additional for 6T tokens, then context-extended to 128K context size. But DeepSeek's base model seems to have been educated through accurate sources while introducing a layer of censorship or withholding sure information by way of a further safeguarding layer.
If you adored this short article and you would certainly like to get even more information regarding ديب سيك kindly visit our own internet site.
댓글목록
등록된 댓글이 없습니다.


