






Ethics and Psychology
페이지 정보
작성자 Carolyn 작성일25-03-01 19:50 조회6회 댓글0건본문
 After this training part, DeepSeek refined the model by combining it with different supervised training strategies to shine it and create the ultimate version of R1, which retains this component whereas including consistency and refinement. This second, as illustrated in Table 3, happens in an intermediate version of the mannequin. Otherwise, it routes the request to the model. Let's be sincere; we all have screamed at some point because a new model supplier doesn't comply with the OpenAI SDK format for textual content, picture, or embedding technology. Here is how one can create embedding of paperwork. Usually, embedding technology can take a very long time, slowing down the complete pipeline. Now, right here is how you can extract structured knowledge from LLM responses. If you have performed with LLM outputs, you recognize it can be challenging to validate structured responses. It will possibly seamlessly integrate with present Postgres databases. Modern RAG applications are incomplete without vector databases.
After this training part, DeepSeek refined the model by combining it with different supervised training strategies to shine it and create the ultimate version of R1, which retains this component whereas including consistency and refinement. This second, as illustrated in Table 3, happens in an intermediate version of the mannequin. Otherwise, it routes the request to the model. Let's be sincere; we all have screamed at some point because a new model supplier doesn't comply with the OpenAI SDK format for textual content, picture, or embedding technology. Here is how one can create embedding of paperwork. Usually, embedding technology can take a very long time, slowing down the complete pipeline. Now, right here is how you can extract structured knowledge from LLM responses. If you have performed with LLM outputs, you recognize it can be challenging to validate structured responses. It will possibly seamlessly integrate with present Postgres databases. Modern RAG applications are incomplete without vector databases.
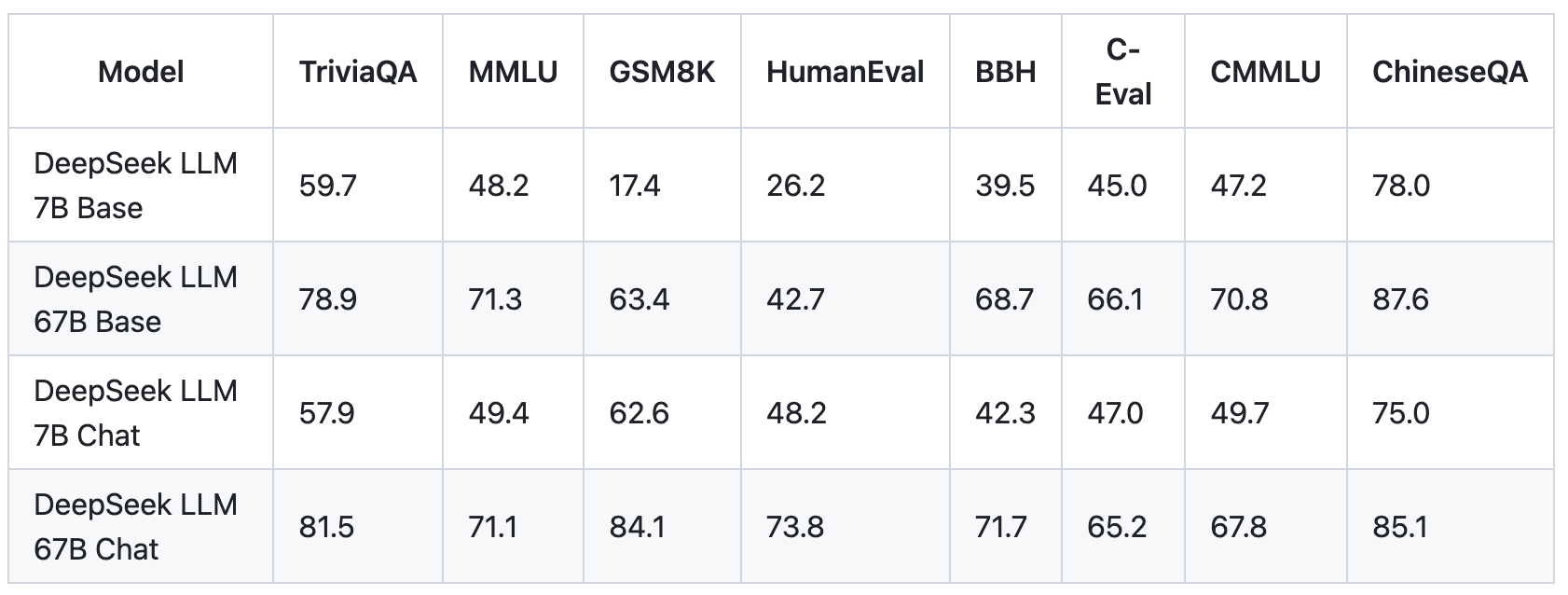 Own objective-setting, and changing its own weights, are two areas where we haven’t but seen main papers emerge, however I think they’re both going to be somewhat attainable subsequent 12 months. Sam Altman, CEO of OpenAI, last 12 months stated the AI business would want trillions of dollars in funding to help the development of high-in-demand chips needed to energy the electricity-hungry knowledge centers that run the sector’s complicated fashions. To know what’s so spectacular about Deepseek Online chat, one has to look again to final month, when OpenAI launched its own technical breakthrough: the complete launch of o1, a brand new kind of AI mannequin that, not like all the "GPT"-fashion programs before it, appears capable of "reason" by means of challenging problems. For engineering-associated duties, while Deepseek free-V3 performs barely below Claude-Sonnet-3.5, it still outpaces all other fashions by a significant margin, demonstrating its competitiveness across numerous technical benchmarks. Based on a paper authored by the corporate, DeepSeek-R1 beats the industry’s leading models like OpenAI o1 on a number of math and reasoning benchmarks.
Own objective-setting, and changing its own weights, are two areas where we haven’t but seen main papers emerge, however I think they’re both going to be somewhat attainable subsequent 12 months. Sam Altman, CEO of OpenAI, last 12 months stated the AI business would want trillions of dollars in funding to help the development of high-in-demand chips needed to energy the electricity-hungry knowledge centers that run the sector’s complicated fashions. To know what’s so spectacular about Deepseek Online chat, one has to look again to final month, when OpenAI launched its own technical breakthrough: the complete launch of o1, a brand new kind of AI mannequin that, not like all the "GPT"-fashion programs before it, appears capable of "reason" by means of challenging problems. For engineering-associated duties, while Deepseek free-V3 performs barely below Claude-Sonnet-3.5, it still outpaces all other fashions by a significant margin, demonstrating its competitiveness across numerous technical benchmarks. Based on a paper authored by the corporate, DeepSeek-R1 beats the industry’s leading models like OpenAI o1 on a number of math and reasoning benchmarks.
In a analysis paper explaining how they built the technology, DeepSeek’s engineers mentioned they used solely a fraction of the highly specialized pc chips that leading A.I. To address this inefficiency, we recommend that future chips combine FP8 cast and TMA (Tensor Memory Accelerator) entry right into a single fused operation, so quantization may be completed in the course of the switch of activations from global reminiscence to shared memory, avoiding frequent memory reads and writes. DeepSeek also uses less memory than its rivals, finally lowering the associated fee to carry out tasks for users. It permits you to add persistent memory for users, agents, and periods. It permits you to retailer conversations in your preferred vector stores. Haystack lets you effortlessly integrate rankers, vector shops, and parsers into new or existing pipelines, making it simple to show your prototypes into production-ready options. If you are constructing an application with vector shops, this can be a no-brainer. If you are constructing an app that requires extra extended conversations with chat fashions and do not need to max out credit playing cards, you need caching. If you are constructing a chatbot or Q&A system on customized data, consider Mem0. Speed of execution is paramount in software program improvement, and it is much more vital when building an AI software.
And extra immediately, how can neurologists and neuroethicists consider the ethical implications of the AI instruments accessible to them proper now? From one other terminal, you may work together with the API server utilizing curl. Get began with Mem0 using pip. To get began with FastEmbed, install it utilizing pip. Install LiteLLM utilizing pip. Supervised high-quality-tuning (SFT): A base model is re-trained using labeled information to perform higher on a specific task. The RL stage was followed by another round of SFT knowledge collection. To determine our methodology, we begin by developing an knowledgeable mannequin tailored to a selected area, corresponding to code, mathematics, or common reasoning, utilizing a combined Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) training pipeline. It represents one more step forward in the march to artificial normal intelligence. DeepSeek is a complicated artificial intelligence model designed for complex reasoning and pure language processing. This was adopted by DeepSeek LLM, a 67B parameter mannequin geared toward competing with other giant language fashions. Before sending a question to the LLM, it searches the vector store; if there's successful, it fetches it. Sounds attention-grabbing. Is there any particular cause for favouring LlamaIndex over LangChain? DROP: A studying comprehension benchmark requiring discrete reasoning over paragraphs.
댓글목록
등록된 댓글이 없습니다.


