






Top Deepseek Guide!
페이지 정보
작성자 Terrence 작성일25-02-01 06:42 조회5회 댓글0건본문
 Whether you are a knowledge scientist, enterprise leader, or tech enthusiast, DeepSeek R1 is your ultimate tool to unlock the true potential of your data. Enjoy experimenting with DeepSeek-R1 and exploring the potential of native AI models. By following this guide, you've got successfully set up DeepSeek-R1 on your native machine using Ollama. GUi for local version? Visit the Ollama webpage and download the model that matches your working system. Please make sure that you are utilizing the newest model of textual content-era-webui. The newest version, DeepSeek-V2, has undergone vital optimizations in architecture and efficiency, with a 42.5% discount in training prices and a 93.3% reduction in inference costs. This not only improves computational efficiency but also considerably reduces training prices and inference time. Mixture of Experts (MoE) Architecture: DeepSeek-V2 adopts a mixture of consultants mechanism, permitting the mannequin to activate only a subset of parameters throughout inference. DeepSeek-V2 is a state-of-the-art language model that makes use of a Transformer structure mixed with an progressive MoE system and a specialised consideration mechanism known as Multi-Head Latent Attention (MLA). DeepSeek is a complicated open-supply Large Language Model (LLM). LobeChat is an open-supply large language model dialog platform dedicated to creating a refined interface and wonderful user experience, supporting seamless integration with DeepSeek fashions.
Whether you are a knowledge scientist, enterprise leader, or tech enthusiast, DeepSeek R1 is your ultimate tool to unlock the true potential of your data. Enjoy experimenting with DeepSeek-R1 and exploring the potential of native AI models. By following this guide, you've got successfully set up DeepSeek-R1 on your native machine using Ollama. GUi for local version? Visit the Ollama webpage and download the model that matches your working system. Please make sure that you are utilizing the newest model of textual content-era-webui. The newest version, DeepSeek-V2, has undergone vital optimizations in architecture and efficiency, with a 42.5% discount in training prices and a 93.3% reduction in inference costs. This not only improves computational efficiency but also considerably reduces training prices and inference time. Mixture of Experts (MoE) Architecture: DeepSeek-V2 adopts a mixture of consultants mechanism, permitting the mannequin to activate only a subset of parameters throughout inference. DeepSeek-V2 is a state-of-the-art language model that makes use of a Transformer structure mixed with an progressive MoE system and a specialised consideration mechanism known as Multi-Head Latent Attention (MLA). DeepSeek is a complicated open-supply Large Language Model (LLM). LobeChat is an open-supply large language model dialog platform dedicated to creating a refined interface and wonderful user experience, supporting seamless integration with DeepSeek fashions.
Even so, the kind of answers they generate appears to rely on the extent of censorship and the language of the immediate. Language Understanding: DeepSeek performs well in open-ended era duties in English and Chinese, showcasing its multilingual processing capabilities. Extended Context Window: DeepSeek can process lengthy text sequences, making it nicely-suited to duties like complicated code sequences and detailed conversations. Build - Tony Fadell 2024-02-24 Introduction Tony Fadell is CEO of nest (purchased by google ), and instrumental in constructing merchandise at Apple just like the iPod and Deepseek (diaspora.mifritscher.de) the iPhone. Singlestore is an all-in-one information platform to construct AI/ML applications. If you want to extend your studying and build a simple RAG utility, you can comply with this tutorial. I used 7b one in the above tutorial. I used 7b one in my tutorial. It is identical however with less parameter one. Step 1: Collect code data from GitHub and apply the same filtering guidelines as StarCoder Data to filter knowledge. Say hey to DeepSeek R1-the AI-powered platform that’s altering the principles of data analytics! It is deceiving to not specifically say what mannequin you're working. Block scales and mins are quantized with four bits. Again, just to emphasize this point, all of the choices DeepSeek made within the design of this model solely make sense in case you are constrained to the H800; if DeepSeek had entry to H100s, they in all probability would have used a larger training cluster with much fewer optimizations particularly targeted on overcoming the lack of bandwidth.
Does that make sense going forward? Depending in your internet velocity, this may take a while. When you don’t believe me, just take a learn of some experiences humans have taking part in the game: "By the time I end exploring the level to my satisfaction, I’m level 3. I've two food rations, a pancake, and a newt corpse in my backpack for food, and I’ve discovered three more potions of various colours, all of them nonetheless unidentified. The portable Wasm app automatically takes advantage of the hardware accelerators (eg GPUs) I have on the gadget. Create a bot and assign it to the Meta Business App. This model demonstrates how LLMs have improved for programming tasks. For example, if you have a piece of code with something missing in the center, the model can predict what needs to be there based mostly on the surrounding code. There were quite just a few things I didn’t explore right here. The lengthy-context capability of DeepSeek-V3 is additional validated by its greatest-in-class efficiency on LongBench v2, a dataset that was launched just a few weeks before the launch of DeepSeek V3. Start Now. Free access to DeepSeek-V3.
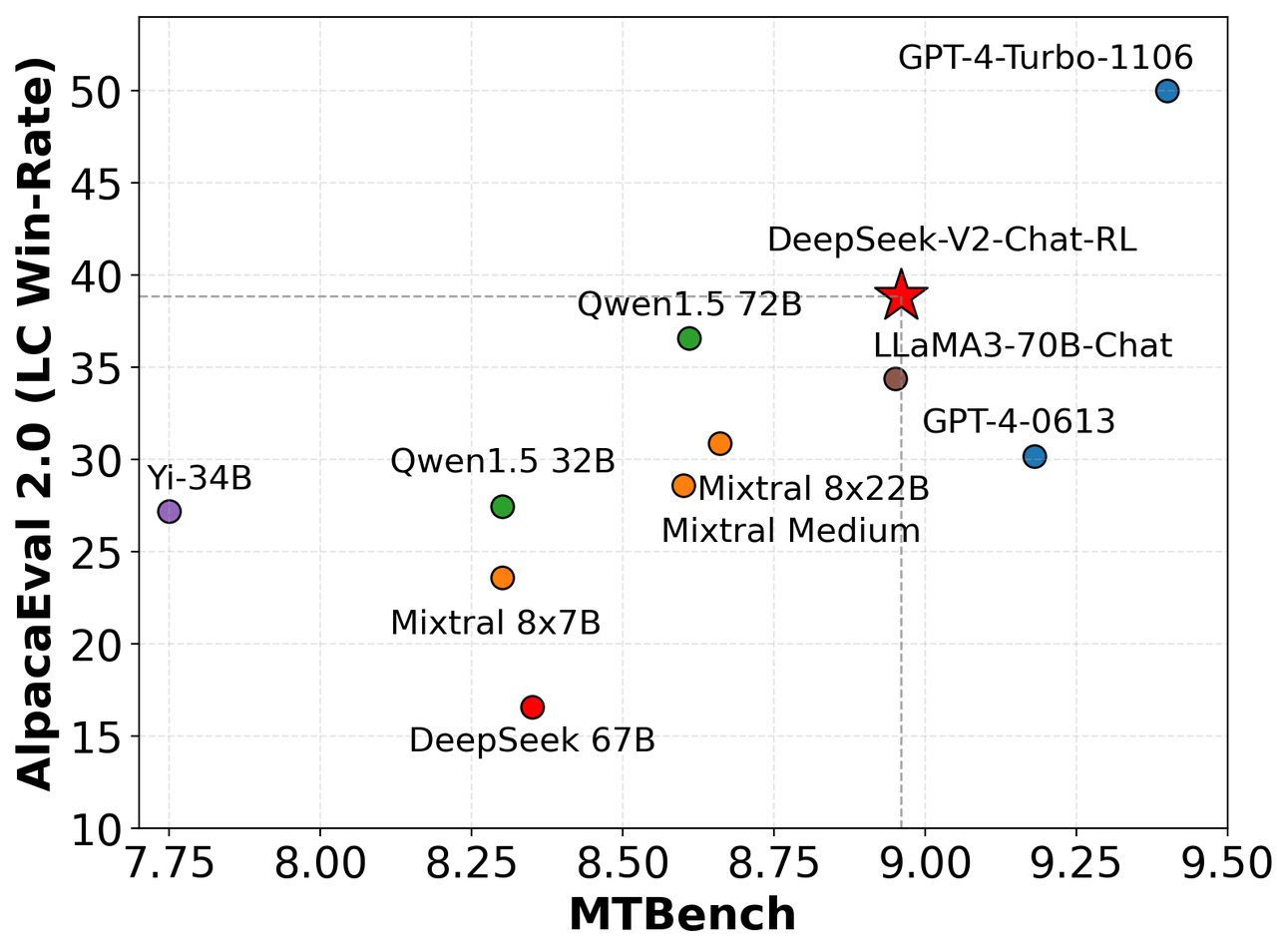 To receive new posts and assist my work, consider becoming a free or paid subscriber. I am aware of NextJS's "static output" but that does not support most of its features and more importantly, isn't an SPA however fairly a Static Site Generator the place every web page is reloaded, just what React avoids taking place. Follow the installation directions offered on the site. Just to present an thought about how the problems appear to be, AIMO provided a 10-problem coaching set open to the public. Mathematics and Reasoning: DeepSeek demonstrates robust capabilities in fixing mathematical issues and reasoning tasks. The mannequin appears to be like good with coding tasks additionally. Good one, it helped me so much. Upon nearing convergence within the RL process, we create new SFT data by way of rejection sampling on the RL checkpoint, combined with supervised knowledge from DeepSeek-V3 in domains reminiscent of writing, factual QA, and self-cognition, and then retrain the DeepSeek-V3-Base model. EAGLE: speculative sampling requires rethinking function uncertainty. DeepSeek-AI (2024a) DeepSeek-AI. Deepseek-coder-v2: Breaking the barrier of closed-source fashions in code intelligence. Both OpenAI and Mistral moved from open-supply to closed-source. OpenAI o1 equivalent domestically, which isn't the case. It's designed to supply extra pure, partaking, and dependable conversational experiences, showcasing Anthropic’s commitment to creating user-pleasant and efficient AI solutions.
To receive new posts and assist my work, consider becoming a free or paid subscriber. I am aware of NextJS's "static output" but that does not support most of its features and more importantly, isn't an SPA however fairly a Static Site Generator the place every web page is reloaded, just what React avoids taking place. Follow the installation directions offered on the site. Just to present an thought about how the problems appear to be, AIMO provided a 10-problem coaching set open to the public. Mathematics and Reasoning: DeepSeek demonstrates robust capabilities in fixing mathematical issues and reasoning tasks. The mannequin appears to be like good with coding tasks additionally. Good one, it helped me so much. Upon nearing convergence within the RL process, we create new SFT data by way of rejection sampling on the RL checkpoint, combined with supervised knowledge from DeepSeek-V3 in domains reminiscent of writing, factual QA, and self-cognition, and then retrain the DeepSeek-V3-Base model. EAGLE: speculative sampling requires rethinking function uncertainty. DeepSeek-AI (2024a) DeepSeek-AI. Deepseek-coder-v2: Breaking the barrier of closed-source fashions in code intelligence. Both OpenAI and Mistral moved from open-supply to closed-source. OpenAI o1 equivalent domestically, which isn't the case. It's designed to supply extra pure, partaking, and dependable conversational experiences, showcasing Anthropic’s commitment to creating user-pleasant and efficient AI solutions.
When you loved this article and you want to receive more information about ديب سيك مجانا please visit our own internet site.
댓글목록
등록된 댓글이 없습니다.


