






The Untold Story on Deepseek That You will Need to Read or Be Unnotice…
페이지 정보
작성자 Christopher Per… 작성일25-02-01 21:04 조회4회 댓글0건본문
But like different AI corporations in China, DeepSeek has been affected by U.S. Why this issues - compute is the one factor standing between Chinese AI firms and the frontier labs within the West: This interview is the latest instance of how access to compute is the one remaining factor that differentiates Chinese labs from Western labs. Chinese AI lab DeepSeek broke into the mainstream consciousness this week after its chatbot app rose to the highest of the Apple App Store charts. The corporate reportedly aggressively recruits doctorate AI researchers from high Chinese universities. Until now, China’s censored web has largely affected only Chinese customers. DeepSeek’s rise highlights China’s growing dominance in chopping-edge AI technology. Being Chinese-developed AI, they’re topic to benchmarking by China’s web regulator to ensure that its responses "embody core socialist values." In deepseek ai china’s chatbot app, for instance, R1 won’t answer questions about Tiananmen Square or Taiwan’s autonomy. Unlike nuclear weapons, for instance, AI doesn't have a comparable "enrichment" metric that marks a transition to weaponization. In keeping with Clem Delangue, the CEO of Hugging Face, one of the platforms hosting DeepSeek’s models, developers on Hugging Face have created over 500 "derivative" models of R1 which have racked up 2.5 million downloads combined.
 DeepSeek unveiled its first set of fashions - DeepSeek Coder, DeepSeek LLM, and DeepSeek Chat - in November 2023. Nevertheless it wasn’t till final spring, when the startup released its next-gen DeepSeek-V2 family of models, that the AI trade started to take notice. DeepSeek released its R1-Lite-Preview mannequin in November 2024, claiming that the new mannequin may outperform OpenAI’s o1 family of reasoning fashions (and accomplish that at a fraction of the value). Released in January, DeepSeek claims R1 performs in addition to OpenAI’s o1 model on key benchmarks. DeepSeek-V2, a basic-purpose textual content- and image-analyzing system, carried out properly in varied AI benchmarks - and was far cheaper to run than comparable fashions at the time. With layoffs and slowed hiring in tech, the demand for alternatives far outweighs the provision, sparking discussions on workforce readiness and trade growth. AI race and whether the demand for AI chips will sustain. Participate within the quiz primarily based on this newsletter and the lucky five winners will get a chance to win a espresso mug! Get started with CopilotKit using the following command. We additional positive-tune the bottom mannequin with 2B tokens of instruction knowledge to get instruction-tuned fashions, namedly DeepSeek-Coder-Instruct.
DeepSeek unveiled its first set of fashions - DeepSeek Coder, DeepSeek LLM, and DeepSeek Chat - in November 2023. Nevertheless it wasn’t till final spring, when the startup released its next-gen DeepSeek-V2 family of models, that the AI trade started to take notice. DeepSeek released its R1-Lite-Preview mannequin in November 2024, claiming that the new mannequin may outperform OpenAI’s o1 family of reasoning fashions (and accomplish that at a fraction of the value). Released in January, DeepSeek claims R1 performs in addition to OpenAI’s o1 model on key benchmarks. DeepSeek-V2, a basic-purpose textual content- and image-analyzing system, carried out properly in varied AI benchmarks - and was far cheaper to run than comparable fashions at the time. With layoffs and slowed hiring in tech, the demand for alternatives far outweighs the provision, sparking discussions on workforce readiness and trade growth. AI race and whether the demand for AI chips will sustain. Participate within the quiz primarily based on this newsletter and the lucky five winners will get a chance to win a espresso mug! Get started with CopilotKit using the following command. We additional positive-tune the bottom mannequin with 2B tokens of instruction knowledge to get instruction-tuned fashions, namedly DeepSeek-Coder-Instruct.
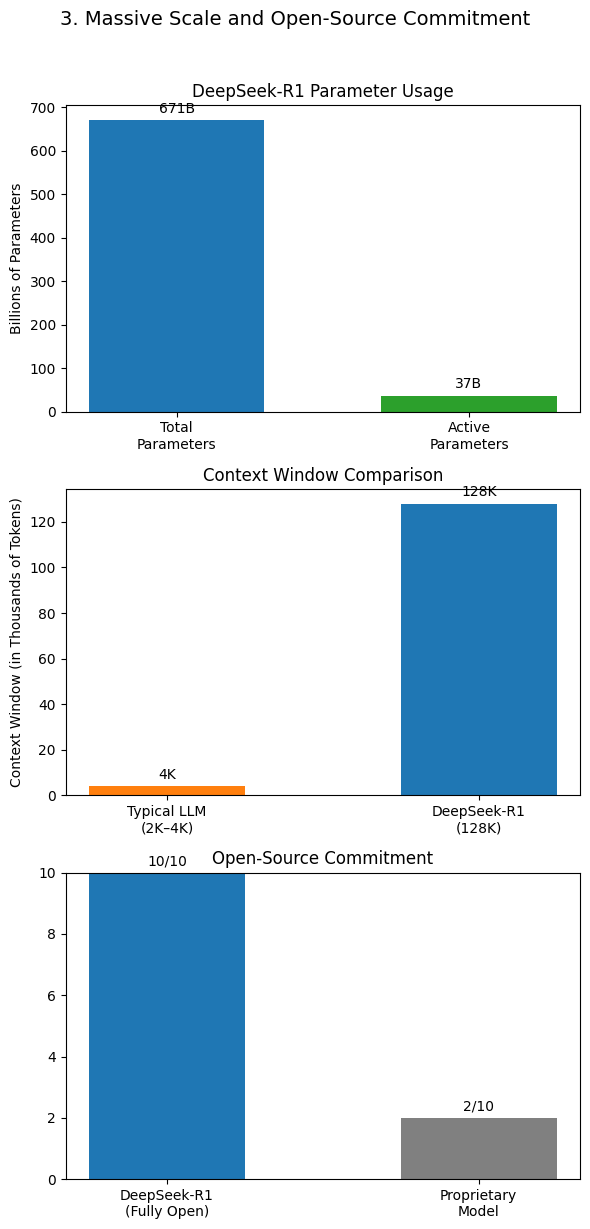
To prepare certainly one of its more recent fashions, the company was forced to make use of Nvidia H800 chips, a less-highly effective model of a chip, the H100, available to U.S. Users ought to improve to the most recent Cody version of their respective IDE to see the benefits. The goal is to see if the mannequin can remedy the programming job without being explicitly proven the documentation for the API replace. India is developing a generative AI mannequin with 18,000 GPUs, aiming to rival OpenAI and DeepSeek. AI enthusiast Liang Wenfeng co-based High-Flyer in 2015. Wenfeng, who reportedly began dabbling in buying and selling whereas a student at Zhejiang University, launched High-Flyer Capital Management as a hedge fund in 2019 targeted on creating and deploying AI algorithms. In 2023, High-Flyer began DeepSeek as a lab dedicated to researching AI tools separate from its monetary business. If DeepSeek has a business mannequin, it’s not clear what that model is, precisely. As for what DeepSeek’s future may hold, it’s not clear. It’s crucial to refer to each nation’s legal guidelines and values when evaluating the appropriateness of such a claim.
In addition, China has additionally formulated a series of laws and regulations to protect citizens’ reputable rights and interests and social order. When we requested the Baichuan internet model the same question in English, however, it gave us a response that each properly explained the distinction between the "rule of law" and "rule by law" and asserted that China is a rustic with rule by legislation. The researchers evaluated their model on the Lean four miniF2F and FIMO benchmarks, which comprise hundreds of mathematical problems. The proofs have been then verified by Lean four to make sure their correctness. Mixture of Experts (MoE) Architecture: DeepSeek-V2 adopts a mixture of experts mechanism, allowing the mannequin to activate solely a subset of parameters during inference. From day one, DeepSeek constructed its personal information center clusters for mannequin coaching. But such training knowledge is not available in sufficient abundance. He knew the data wasn’t in any other systems as a result of the journals it came from hadn’t been consumed into the AI ecosystem - there was no trace of them in any of the training units he was conscious of, and fundamental data probes on publicly deployed models didn’t seem to indicate familiarity. Training data: Compared to the original DeepSeek-Coder, DeepSeek-Coder-V2 expanded the training information significantly by including an extra 6 trillion tokens, growing the whole to 10.2 trillion tokens.
Should you loved this short article and you would want to receive details with regards to ديب سيك kindly visit the website.
댓글목록
등록된 댓글이 없습니다.


