






9 Tips on Deepseek You Can't Afford To overlook
페이지 정보
작성자 Reina Fergusson 작성일25-02-03 10:29 조회3회 댓글0건본문
 We introduce an progressive methodology to distill reasoning capabilities from the lengthy-Chain-of-Thought (CoT) mannequin, particularly from one of many DeepSeek R1 series fashions, into standard LLMs, significantly DeepSeek-V3. One of the main features that distinguishes the DeepSeek LLM household from other LLMs is the superior efficiency of the 67B Base mannequin, which outperforms the Llama2 70B Base mannequin in a number of domains, resembling reasoning, coding, arithmetic, and Chinese comprehension. The DeepSeek LLM household consists of 4 models: DeepSeek LLM 7B Base, DeepSeek LLM 67B Base, DeepSeek LLM 7B Chat, and DeepSeek 67B Chat. Another notable achievement of the DeepSeek LLM family is the LLM 7B Chat and 67B Chat fashions, which are specialised for conversational duties. By open-sourcing its models, code, and information, DeepSeek LLM hopes to promote widespread AI analysis and business functions. The issue units are additionally open-sourced for further research and comparability. DeepSeek AI has determined to open-supply both the 7 billion and 67 billion parameter variations of its models, including the base and chat variants, to foster widespread AI analysis and commercial functions.
We introduce an progressive methodology to distill reasoning capabilities from the lengthy-Chain-of-Thought (CoT) mannequin, particularly from one of many DeepSeek R1 series fashions, into standard LLMs, significantly DeepSeek-V3. One of the main features that distinguishes the DeepSeek LLM household from other LLMs is the superior efficiency of the 67B Base mannequin, which outperforms the Llama2 70B Base mannequin in a number of domains, resembling reasoning, coding, arithmetic, and Chinese comprehension. The DeepSeek LLM household consists of 4 models: DeepSeek LLM 7B Base, DeepSeek LLM 67B Base, DeepSeek LLM 7B Chat, and DeepSeek 67B Chat. Another notable achievement of the DeepSeek LLM family is the LLM 7B Chat and 67B Chat fashions, which are specialised for conversational duties. By open-sourcing its models, code, and information, DeepSeek LLM hopes to promote widespread AI analysis and business functions. The issue units are additionally open-sourced for further research and comparability. DeepSeek AI has determined to open-supply both the 7 billion and 67 billion parameter variations of its models, including the base and chat variants, to foster widespread AI analysis and commercial functions.
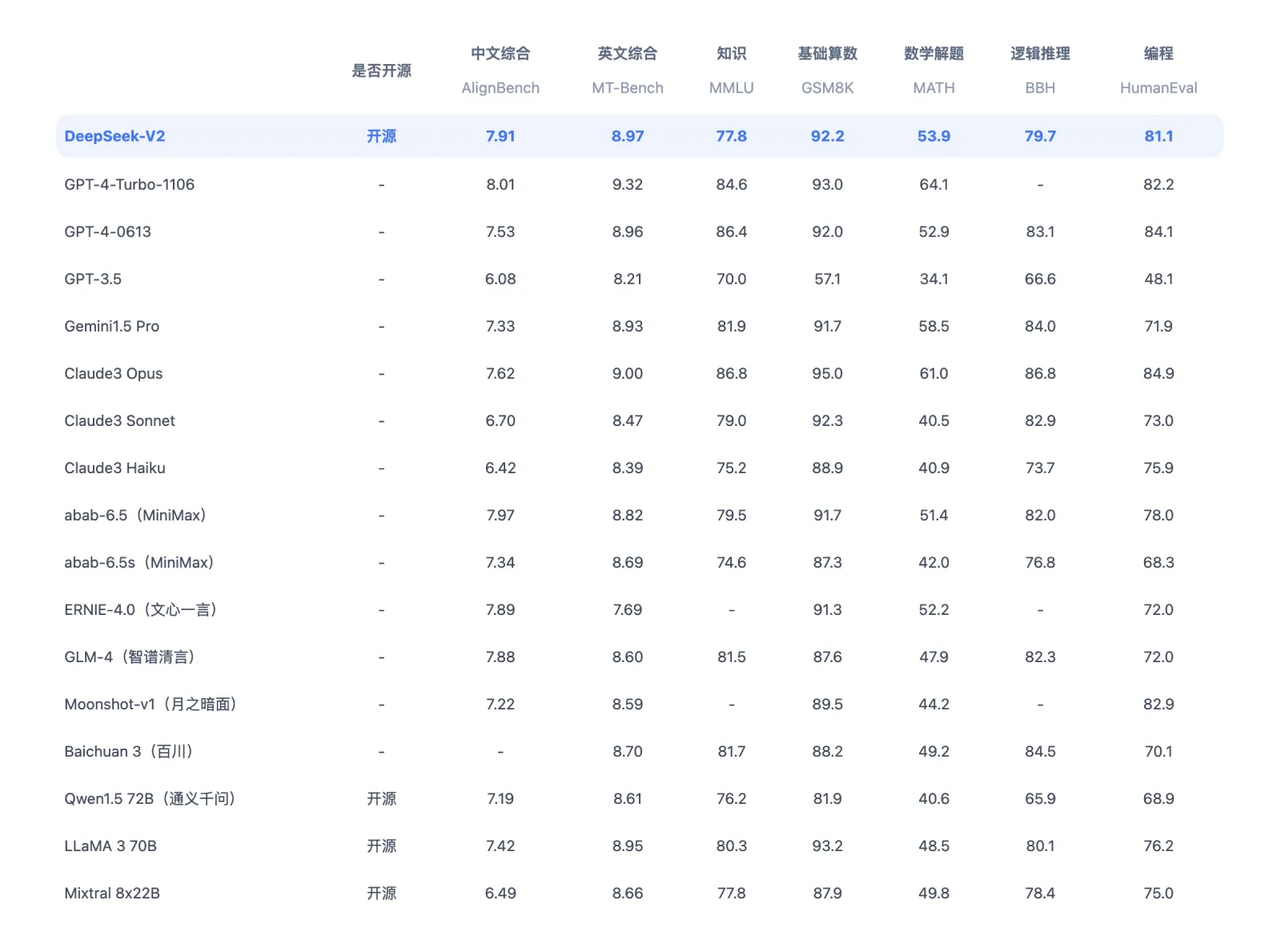 For instance, a 175 billion parameter mannequin that requires 512 GB - 1 TB of RAM in FP32 might potentially be reduced to 256 GB - 512 GB of RAM by utilizing FP16. A normal use mannequin that combines advanced analytics capabilities with an unlimited thirteen billion parameter rely, enabling it to perform in-depth information analysis and support complex decision-making processes. The coaching regimen employed large batch sizes and a multi-step studying fee schedule, ensuring sturdy and efficient learning capabilities. This web page supplies data on the big Language Models (LLMs) that are available in the Prediction Guard API. Multi-Token Prediction (MTP) is in development, and progress could be tracked within the optimization plan. You'll be able to then use a remotely hosted or SaaS model for the other expertise. Recently introduced for our free deepseek and Pro customers, DeepSeek-V2 is now the advisable default mannequin for Enterprise clients too. Claude 3.5 Sonnet has shown to be the most effective performing models available in the market, and is the default model for our free deepseek and Pro users. BYOK prospects should check with their supplier in the event that they support Claude 3.5 Sonnet for his or her specific deployment environment. We’ve just launched our first scripted video, which you'll be able to try right here.
For instance, a 175 billion parameter mannequin that requires 512 GB - 1 TB of RAM in FP32 might potentially be reduced to 256 GB - 512 GB of RAM by utilizing FP16. A normal use mannequin that combines advanced analytics capabilities with an unlimited thirteen billion parameter rely, enabling it to perform in-depth information analysis and support complex decision-making processes. The coaching regimen employed large batch sizes and a multi-step studying fee schedule, ensuring sturdy and efficient learning capabilities. This web page supplies data on the big Language Models (LLMs) that are available in the Prediction Guard API. Multi-Token Prediction (MTP) is in development, and progress could be tracked within the optimization plan. You'll be able to then use a remotely hosted or SaaS model for the other expertise. Recently introduced for our free deepseek and Pro customers, DeepSeek-V2 is now the advisable default mannequin for Enterprise clients too. Claude 3.5 Sonnet has shown to be the most effective performing models available in the market, and is the default model for our free deepseek and Pro users. BYOK prospects should check with their supplier in the event that they support Claude 3.5 Sonnet for his or her specific deployment environment. We’ve just launched our first scripted video, which you'll be able to try right here.
Also, with any long tail search being catered to with more than 98% accuracy, you may as well cater to any deep Seo for any type of key phrases. That is to make sure consistency between the outdated Hermes and new, for anyone who wanted to maintain Hermes as similar to the outdated one, simply extra capable. The Hermes 3 series builds and expands on the Hermes 2 set of capabilities, including extra highly effective and dependable function calling and structured output capabilities, generalist assistant capabilities, and improved code era abilities. That is extra difficult than updating an LLM's knowledge about basic info, as the mannequin should motive concerning the semantics of the modified operate relatively than simply reproducing its syntax. DHS has special authorities to transmit information relating to individual or group AIS account exercise to, reportedly, the FBI, the CIA, the NSA, the State Department, the Department of Justice, the Department of Health and Human Services, and more. Instead of just specializing in particular person chip efficiency beneficial properties by way of continuous node advancement-similar to from 7 nanometers (nm) to 5 nm to 3 nm-it has started to recognize the importance of system-degree performance beneficial properties afforded by APT.
I don’t get "interconnected in pairs." An SXM A100 node should have eight GPUs connected all-to-all over an NVSwitch. Each node in the H800 cluster accommodates 8 GPUs related utilizing NVLink and NVSwitch inside nodes. The downside is that the model’s political views are a bit… These evaluations successfully highlighted the model’s distinctive capabilities in handling previously unseen exams and duties. DeepSeek AI, a Chinese AI startup, has announced the launch of the DeepSeek LLM household, a set of open-source large language models (LLMs) that achieve exceptional results in varied language tasks. It additionally demonstrates exceptional talents in coping with previously unseen exams and duties. Hermes three is a generalist language mannequin with many enhancements over Hermes 2, together with superior agentic capabilities, a lot better roleplaying, reasoning, multi-turn dialog, lengthy context coherence, and improvements across the board. In key areas resembling reasoning, coding, mathematics, and Chinese comprehension, LLM outperforms different language models. The LLM was educated on a large dataset of 2 trillion tokens in each English and Chinese, using architectures resembling LLaMA and Grouped-Query Attention. What is the difference between deepseek (click the next internet site) LLM and other language models? The ethos of the Hermes collection of models is targeted on aligning LLMs to the person, with highly effective steering capabilities and control given to the end consumer.
댓글목록
등록된 댓글이 없습니다.


