






The Way to Get A Deepseek?
페이지 정보
작성자 Gavin 작성일25-02-08 16:49 조회5회 댓글0건본문
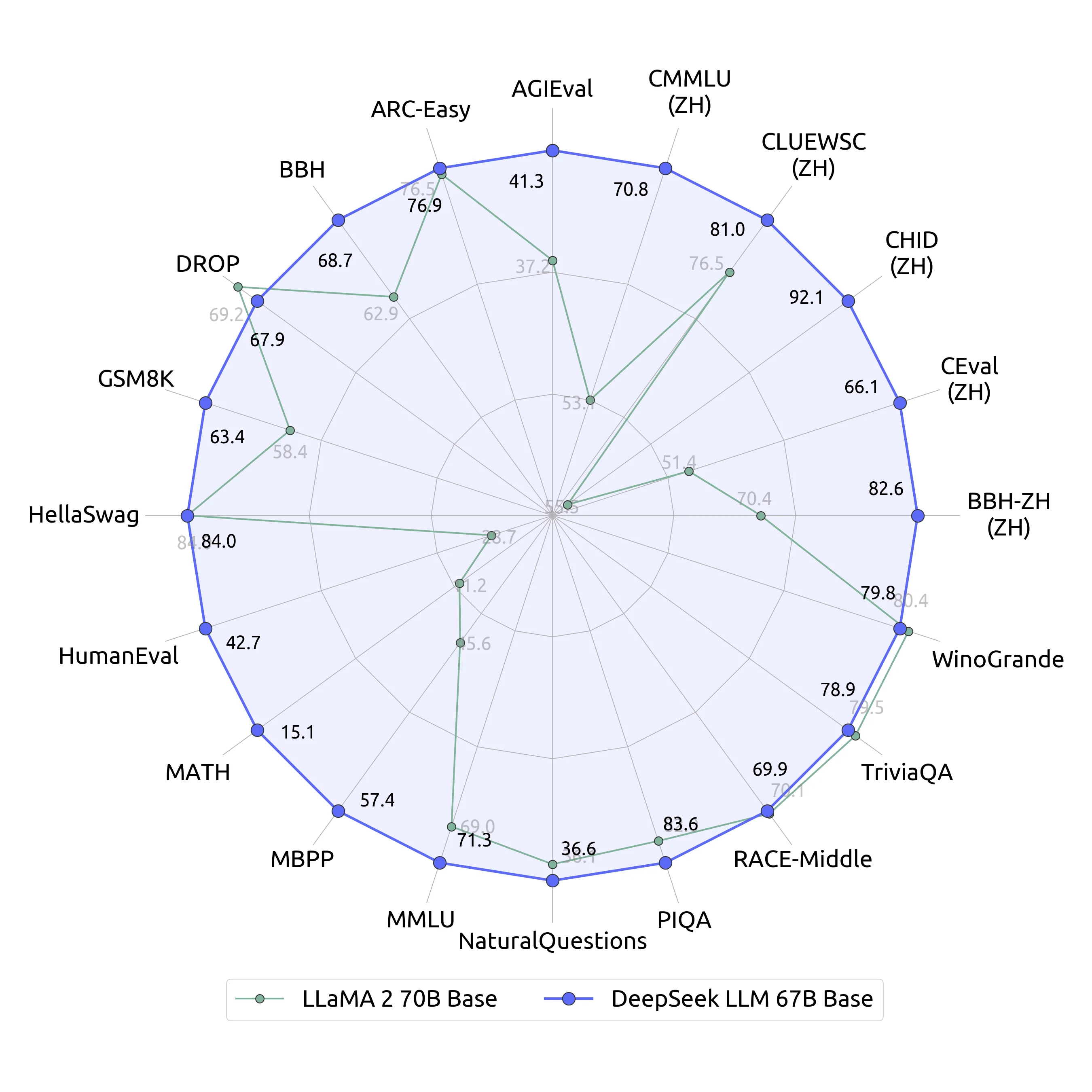 This qualitative leap within the capabilities of DeepSeek LLMs demonstrates their proficiency throughout a wide array of functions. It gives React components like textual content areas, popups, sidebars, and chatbots to reinforce any application with AI capabilities. For Best Performance: Go for a machine with a excessive-end GPU (like NVIDIA's newest RTX 3090 or RTX 4090) or twin GPU setup to accommodate the biggest models (65B and 70B). A system with ample RAM (minimum sixteen GB, but sixty four GB greatest) would be optimum. DeepSeek's launch comes scorching on the heels of the announcement of the most important non-public investment in AI infrastructure ever: Project Stargate, announced January 21, is a $500 billion funding by OpenAI, Oracle, SoftBank, and MGX, who will partner with firms like Microsoft and NVIDIA to construct out AI-targeted amenities within the US. The mixture of experts, being similar to the gaussian mixture mannequin, can be educated by the expectation-maximization algorithm, similar to gaussian mixture models.
This qualitative leap within the capabilities of DeepSeek LLMs demonstrates their proficiency throughout a wide array of functions. It gives React components like textual content areas, popups, sidebars, and chatbots to reinforce any application with AI capabilities. For Best Performance: Go for a machine with a excessive-end GPU (like NVIDIA's newest RTX 3090 or RTX 4090) or twin GPU setup to accommodate the biggest models (65B and 70B). A system with ample RAM (minimum sixteen GB, but sixty four GB greatest) would be optimum. DeepSeek's launch comes scorching on the heels of the announcement of the most important non-public investment in AI infrastructure ever: Project Stargate, announced January 21, is a $500 billion funding by OpenAI, Oracle, SoftBank, and MGX, who will partner with firms like Microsoft and NVIDIA to construct out AI-targeted amenities within the US. The mixture of experts, being similar to the gaussian mixture mannequin, can be educated by the expectation-maximization algorithm, similar to gaussian mixture models.
Explore all variations of the model, their file codecs like GGML, GPTQ, and HF, and understand the hardware necessities for native inference. In words, the consultants that, in hindsight, seemed like the great experts to consult, are requested to learn on the example. The specialists that, in hindsight, weren't, are left alone. Models are pre-skilled using 1.8T tokens and a 4K window dimension on this step. The interleaved window consideration was contributed by Ying Sheng. They used the pre-norm decoder-only Transformer with RMSNorm as the normalization, SwiGLU in the feedforward layers, rotary positional embedding (RoPE), and grouped-query consideration (GQA). DeepSeek-V2.5 makes use of Multi-Head Latent Attention (MLA) to cut back KV cache and improve inference speed. DeepSeek-V2.5 was launched on September 6, 2024, and is available on Hugging Face with each internet and API entry. From 2018 to 2024, High-Flyer has consistently outperformed the CSI 300 Index. In March 2023, it was reported that high-Flyer was being sued by Shanghai Ruitian Investment LLC for hiring one among its staff.
One can use completely different specialists than gaussian distributions. I've had lots of people ask if they'll contribute. Nobody, together with the one that took the photo, can change this info without invalidating the photo’s cryptographic signature. Rust ML framework with a focus on efficiency, including GPU support, and ease of use. For greatest performance, a modern multi-core CPU is really useful. Having CPU instruction sets like AVX, AVX2, AVX-512 can further improve performance if accessible. "Our work demonstrates that, with rigorous analysis mechanisms like Lean, it is possible to synthesize large-scale, excessive-high quality information. Specifically, through the expectation step, the "burden" for explaining every knowledge level is assigned over the specialists, and through the maximization step, the specialists are trained to improve the reasons they acquired a high burden for, while the gate is trained to enhance its burden project. Models are released as sharded safetensors information. This paper presents a brand new benchmark known as CodeUpdateArena to evaluate how properly large language models (LLMs) can replace their data about evolving code APIs, a essential limitation of current approaches. Learning and Education: LLMs will probably be a fantastic addition to training by offering personalised learning experiences.
At Middleware, we're committed to enhancing developer productivity our open-supply DORA metrics product helps engineering groups improve effectivity by offering insights into PR opinions, figuring out bottlenecks, and suggesting ways to reinforce group performance over 4 necessary metrics. Whether it's enhancing conversations, generating creative content, or offering detailed analysis, these fashions really creates an enormous influence. The mannequin is optimized for both massive-scale inference and small-batch native deployment, enhancing its versatility. Breakthrough in open-supply AI: DeepSeek, a Chinese AI firm, has launched DeepSeek-V2.5, a powerful new open-source language mannequin that combines common language processing and advanced coding capabilities. Introducing DeepSeek, OpenAI’s New Competitor: A Full Breakdown of Its Features, Power, and… The corporate estimates that the R1 mannequin is between 20 and 50 occasions less expensive to run, depending on the task, than OpenAI’s o1. In addition the company acknowledged it had expanded its property too quickly leading to comparable trading methods that made operations more difficult. The model’s success might encourage extra firms and researchers to contribute to open-supply AI initiatives.
When you loved this article and you would love to receive much more information regarding شات DeepSeek generously visit our web site.
댓글목록
등록된 댓글이 없습니다.


