






6 Components That Affect Deepseek
페이지 정보
작성자 Rosella Kail 작성일25-02-22 06:48 조회10회 댓글1건본문
DeepSeek unveiled its first set of fashions - DeepSeek Coder, DeepSeek LLM, and DeepSeek Chat - in November 2023. But it wasn’t until last spring, when the startup launched its subsequent-gen Deepseek Online chat online-V2 household of fashions, that the AI business started to take discover. Under our training framework and infrastructures, training DeepSeek-V3 on every trillion tokens requires solely 180K H800 GPU hours, which is far cheaper than training 72B or 405B dense models. At the large scale, we prepare a baseline MoE mannequin comprising 228.7B complete parameters on 578B tokens. On the small scale, we practice a baseline MoE mannequin comprising 15.7B total parameters on 1.33T tokens. At the big scale, we train a baseline MoE model comprising 228.7B whole parameters on 540B tokens. POSTSUPERSCRIPT within the remaining 167B tokens. POSTSUPERSCRIPT to 64. We substitute all FFNs except for the first three layers with MoE layers. POSTSUPERSCRIPT during the primary 2K steps. POSTSUPERSCRIPT in 4.3T tokens, following a cosine decay curve. 1) Compared with DeepSeek-V2-Base, as a result of enhancements in our model structure, the size-up of the mannequin dimension and coaching tokens, and the enhancement of information high quality, DeepSeek-V3-Base achieves considerably higher efficiency as anticipated. From a more detailed perspective, we evaluate DeepSeek-V3-Base with the opposite open-source base fashions individually.
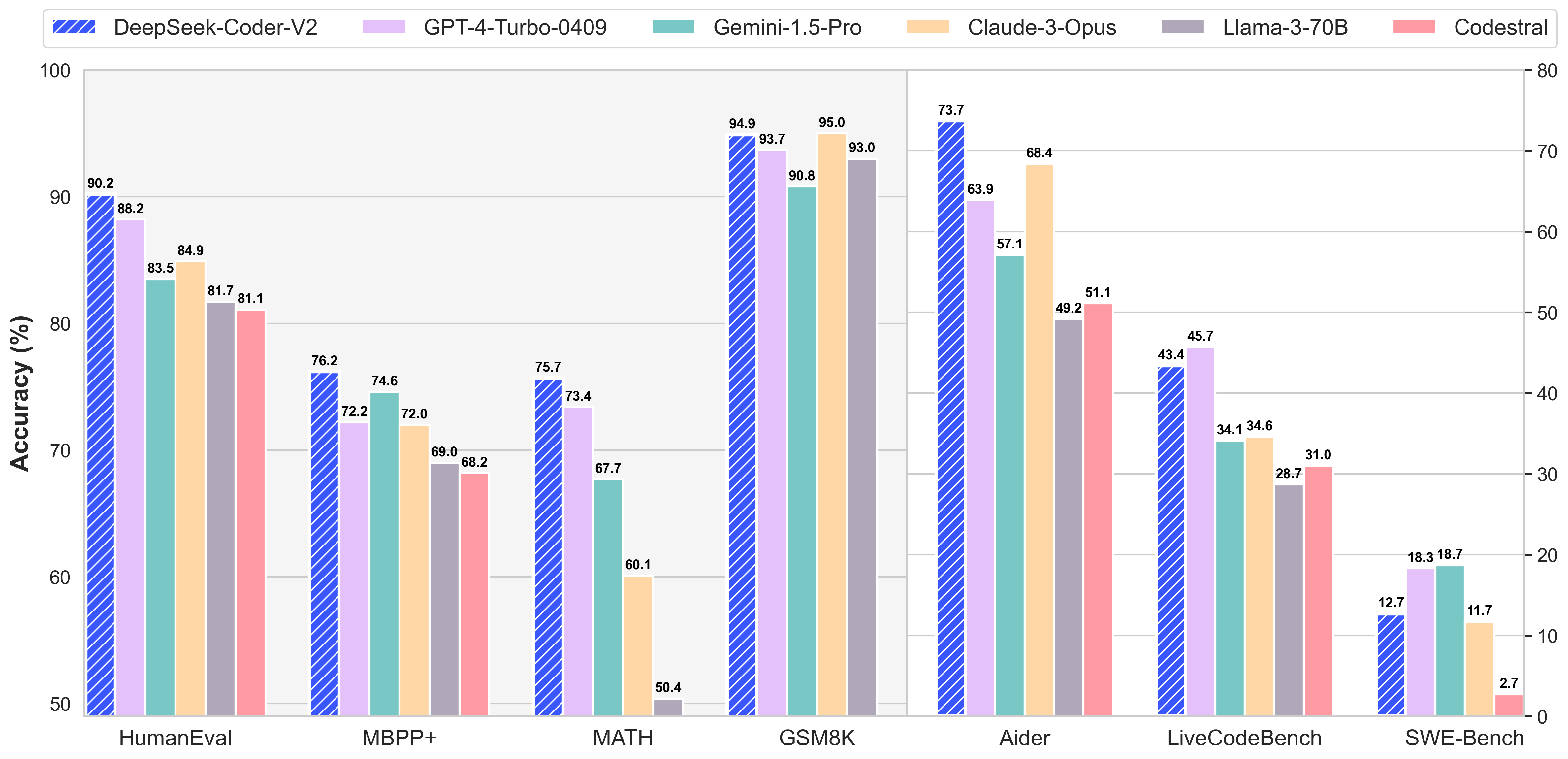 In Table 3, we examine the base mannequin of DeepSeek-V3 with the state-of-the-art open-supply base models, including DeepSeek-V2-Base (DeepSeek-AI, 2024c) (our previous release), Qwen2.5 72B Base (Qwen, 2024b), and LLaMA-3.1 405B Base (AI@Meta, 2024b). We evaluate all these models with our internal evaluation framework, and make sure that they share the same analysis setting. From the table, we will observe that the auxiliary-loss-free strategy consistently achieves higher mannequin efficiency on a lot of the evaluation benchmarks. From the desk, we are able to observe that the MTP strategy consistently enhances the mannequin efficiency on most of the analysis benchmarks. Both have impressive benchmarks compared to their rivals but use considerably fewer resources due to the best way the LLMs have been created. Compared with the sequence-smart auxiliary loss, batch-smart balancing imposes a extra versatile constraint, as it doesn't implement in-area balance on each sequence. On top of those two baseline models, keeping the training information and the opposite architectures the identical, we take away all auxiliary losses and introduce the auxiliary-loss-free balancing technique for comparison. Upon finishing the RL coaching part, we implement rejection sampling to curate excessive-quality SFT knowledge for the ultimate model, the place the professional fashions are used as data era sources. This expert model serves as a data generator for the ultimate model.
In Table 3, we examine the base mannequin of DeepSeek-V3 with the state-of-the-art open-supply base models, including DeepSeek-V2-Base (DeepSeek-AI, 2024c) (our previous release), Qwen2.5 72B Base (Qwen, 2024b), and LLaMA-3.1 405B Base (AI@Meta, 2024b). We evaluate all these models with our internal evaluation framework, and make sure that they share the same analysis setting. From the table, we will observe that the auxiliary-loss-free strategy consistently achieves higher mannequin efficiency on a lot of the evaluation benchmarks. From the desk, we are able to observe that the MTP strategy consistently enhances the mannequin efficiency on most of the analysis benchmarks. Both have impressive benchmarks compared to their rivals but use considerably fewer resources due to the best way the LLMs have been created. Compared with the sequence-smart auxiliary loss, batch-smart balancing imposes a extra versatile constraint, as it doesn't implement in-area balance on each sequence. On top of those two baseline models, keeping the training information and the opposite architectures the identical, we take away all auxiliary losses and introduce the auxiliary-loss-free balancing technique for comparison. Upon finishing the RL coaching part, we implement rejection sampling to curate excessive-quality SFT knowledge for the ultimate model, the place the professional fashions are used as data era sources. This expert model serves as a data generator for the ultimate model.
The experimental results present that, when achieving an identical degree of batch-clever load balance, the batch-wise auxiliary loss also can obtain comparable model efficiency to the auxiliary-loss-free method. Note that because of the changes in our analysis framework over the previous months, the efficiency of DeepSeek-V2-Base exhibits a slight difference from our previously reported outcomes. As well as, we perform language-modeling-based evaluation for Pile-test and use Bits-Per-Byte (BPB) because the metric to ensure honest comparison amongst fashions utilizing completely different tokenizers. DeepSeek claims Janus Pro beats SD 1.5, SDXL, and Pixart Alpha, however it’s necessary to emphasise this should be a comparability in opposition to the bottom, non superb-tuned fashions. If we want certain features of a photo’s origin or provenance to be verifiable, meaning they must be immutable. Having these channels is an emergency possibility that have to be saved open. Then open the app and these sequences ought to open up. The gradient clipping norm is about to 1.0. We make use of a batch size scheduling technique, where the batch dimension is regularly increased from 3072 to 15360 within the training of the first 469B tokens, after which keeps 15360 within the remaining training.
On prime of them, retaining the training data and the other architectures the identical, we append a 1-depth MTP module onto them and train two fashions with the MTP strategy for comparison. With a variety of fashions and newer variations of DeepSeek coming every few months, it has set its roots throughout industries like business, marketing, software, and extra. D is about to 1, i.e., apart from the precise subsequent token, each token will predict one additional token. To validate this, we report and analyze the professional load of a 16B auxiliary-loss-based baseline and a 16B auxiliary-loss-Free DeepSeek online model on totally different domains in the Pile take a look at set. We leverage pipeline parallelism to deploy totally different layers of a model on completely different GPUs, and for every layer, the routed experts will probably be uniformly deployed on 64 GPUs belonging to eight nodes. Each MoE layer consists of 1 shared skilled and 256 routed specialists, where the intermediate hidden dimension of every professional is 2048. Among the many routed consultants, 8 consultants will be activated for each token, and each token shall be ensured to be despatched to at most 4 nodes. However, this trick may introduce the token boundary bias (Lundberg, 2023) when the model processes multi-line prompts without terminal line breaks, significantly for few-shot evaluation prompts.
댓글목록
Coerclefs님의 댓글
Coerclefs 작성일
What is a testnet?
A testnet faucet provides web3 developers with free tokens for deploying, testing, and optimizing smart contracts on test blockchains such as Sepolia, Goerli, and Mumbai.
Because smart contracts on public, mainnet blockchains like Ethereum and Polygon require gas fees to run smart contracts, testnets provide blockchain developers with a network that mirrors production blockchain environments without requiring gas fees that cost real money.
Get Testnet Tokens!
[url=https://defisherlock.com/]az blockchain[/url]
[url=https://x.com/Junior13Luan/status/1888245243155218435]bsc testnet add liquidity4[/url]
[url=https://x.com/Junior13Luan/status/1888245243155218435]ethereum


