






페이지 정보
작성자 Luca Zambrano 작성일25-02-27 07:52 조회1회 댓글0건본문
There are two key limitations of the H800s DeepSeek had to use in comparison with H100s. This design enables overlapping of the 2 operations, sustaining high utilization of Tensor Cores. Notably, our tremendous-grained quantization strategy is extremely according to the idea of microscaling formats (Rouhani et al., 2023b), whereas the Tensor Cores of NVIDIA subsequent-generation GPUs (Blackwell series) have introduced the help for microscaling codecs with smaller quantization granularity (NVIDIA, 2024a). We hope our design can serve as a reference for future work to keep tempo with the newest GPU architectures. Additionally, we leverage the IBGDA (NVIDIA, 2022) technology to further minimize latency and improve communication efficiency. This, by extension, in all probability has everybody nervous about Nvidia, which obviously has an enormous impression on the market. DeepSeek v3 App Free distinguishes itself in the AI market with an exceptionally aggressive pricing strategy that emphasizes accessibility and price-efficiency. This considerate strategy is what makes DeepSeek excel at reasoning duties whereas staying computationally environment friendly. This method ensures that the quantization course of can higher accommodate outliers by adapting the size in keeping with smaller teams of parts.
As illustrated in Figure 7 (a), (1) for activations, we group and scale components on a 1x128 tile basis (i.e., per token per 128 channels); and (2) for weights, we group and scale parts on a 128x128 block foundation (i.e., per 128 enter channels per 128 output channels). In Appendix B.2, we further discuss the coaching instability when we group and scale activations on a block basis in the identical manner as weights quantization. So as to ensure correct scales and simplify the framework, we calculate the maximum absolute value online for every 1x128 activation tile or 128x128 weight block. Additionally, these activations will be transformed from an 1x128 quantization tile to an 128x1 tile within the backward go. However, the current communication implementation relies on expensive SMs (e.g., we allocate 20 out of the 132 SMs available within the H800 GPU for this purpose), which can limit the computational throughput.
Additionally, to boost throughput and disguise the overhead of all-to-all communication, we're also exploring processing two micro-batches with similar computational workloads concurrently within the decoding stage. However, on the H800 structure, it's typical for two WGMMA to persist concurrently: whereas one warpgroup performs the promotion operation, the opposite is able to execute the MMA operation. Before the all-to-all operation at every layer begins, we compute the globally optimum routing scheme on the fly. However, this requires extra careful optimization of the algorithm that computes the globally optimal routing scheme and the fusion with the dispatch kernel to reduce overhead. Given the substantial computation involved in the prefilling stage, the overhead of computing this routing scheme is nearly negligible. For the deployment of DeepSeek-V3, we set 32 redundant consultants for the prefilling stage. The high-load specialists are detected based on statistics collected during the web deployment and are adjusted periodically (e.g., each 10 minutes).
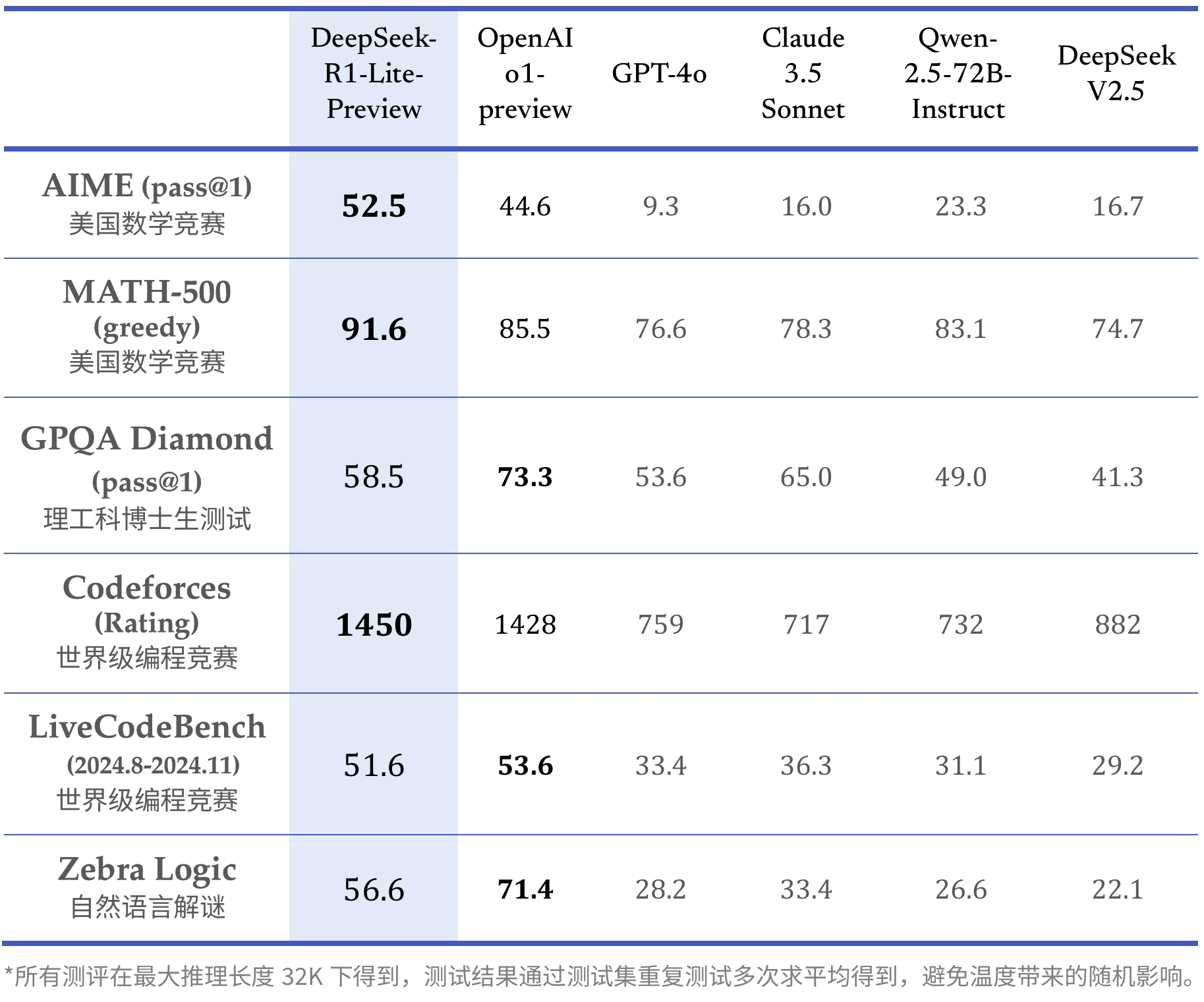 Finally, we're exploring a dynamic redundancy strategy for consultants, where each GPU hosts more specialists (e.g., Sixteen specialists), but only 9 will be activated throughout each inference step. In low-precision training frameworks, overflows and underflows are frequent challenges due to the restricted dynamic range of the FP8 format, which is constrained by its decreased exponent bits. Together with our FP8 training framework, we additional cut back the memory consumption and communication overhead by compressing cached activations and optimizer states into decrease-precision codecs. After determining the set of redundant experts, we carefully rearrange consultants among GPUs within a node based mostly on the noticed loads, striving to steadiness the load across GPUs as much as attainable with out growing the cross-node all-to-all communication overhead. These activations are additionally saved in FP8 with our tremendous-grained quantization methodology, putting a stability between memory effectivity and computational accuracy. To scale back the reminiscence consumption, it's a natural choice to cache activations in FP8 format for the backward move of the Linear operator.
Finally, we're exploring a dynamic redundancy strategy for consultants, where each GPU hosts more specialists (e.g., Sixteen specialists), but only 9 will be activated throughout each inference step. In low-precision training frameworks, overflows and underflows are frequent challenges due to the restricted dynamic range of the FP8 format, which is constrained by its decreased exponent bits. Together with our FP8 training framework, we additional cut back the memory consumption and communication overhead by compressing cached activations and optimizer states into decrease-precision codecs. After determining the set of redundant experts, we carefully rearrange consultants among GPUs within a node based mostly on the noticed loads, striving to steadiness the load across GPUs as much as attainable with out growing the cross-node all-to-all communication overhead. These activations are additionally saved in FP8 with our tremendous-grained quantization methodology, putting a stability between memory effectivity and computational accuracy. To scale back the reminiscence consumption, it's a natural choice to cache activations in FP8 format for the backward move of the Linear operator.
Here is more information regarding DeepSeek r1 look into the webpage.
댓글목록
등록된 댓글이 없습니다.


