






DeepSeek V3: A Code Generation LLM Game Changer?
페이지 정보
작성자 Kelvin 작성일25-03-03 19:59 조회4회 댓글0건본문
 The open-source neighborhood also contributes to improving Deepseek over time. Sure, go ahead and call it left if it makes you're feeling higher but I nonetheless take the European and American left over the left that's embedded into russia and china - been there, finished that, nothing good ever comes out of it and deepseek is right here to back me up with it's solutions. I do not think anyone panics over r1, it is superb but nothing more exceptional than what we have not seen to this point, besides if they thought that solely american companies may produce SOTA-stage fashions which was mistaken already (previous deepseek and qwen models have been already at comparable levels). To improve and develop the Services and to train and enhance our know-how, akin to our machine learning models and algorithms. Built on state-of-the-artwork machine learning algorithms, DeepSeek is engineered to handle complicated duties with precision, speed, and scalability. Curious, how does Deepseek handle edge cases in API error debugging compared to GPT-4 or LLaMA? Benchmark reports present that Deepseek's accuracy fee is 7% higher than GPT-four and 10% higher than LLaMA 2 in actual-world eventualities.
The open-source neighborhood also contributes to improving Deepseek over time. Sure, go ahead and call it left if it makes you're feeling higher but I nonetheless take the European and American left over the left that's embedded into russia and china - been there, finished that, nothing good ever comes out of it and deepseek is right here to back me up with it's solutions. I do not think anyone panics over r1, it is superb but nothing more exceptional than what we have not seen to this point, besides if they thought that solely american companies may produce SOTA-stage fashions which was mistaken already (previous deepseek and qwen models have been already at comparable levels). To improve and develop the Services and to train and enhance our know-how, akin to our machine learning models and algorithms. Built on state-of-the-artwork machine learning algorithms, DeepSeek is engineered to handle complicated duties with precision, speed, and scalability. Curious, how does Deepseek handle edge cases in API error debugging compared to GPT-4 or LLaMA? Benchmark reports present that Deepseek's accuracy fee is 7% higher than GPT-four and 10% higher than LLaMA 2 in actual-world eventualities.
This part showcases sophisticated Deepseek AI brokers in motion, chopping-edge applications, the company's future roadmap, and steerage on harnessing Deepseek's capabilities for enterprise success. Many folks are concerned in regards to the energy calls for and related environmental impression of AI training and inference, and it's heartening to see a improvement that would lead to more ubiquitous AI capabilities with a a lot decrease footprint. And even when sonnet does errors too, iterations with sonnet are sooner than with o1/r1 at least.2. I like the way in which sonnet answers and writes code, and I think I liked qwen 2.5 coder because it reminded me of sonnet (I highly suspect it was skilled on sonnet's output). Moreover, having worked with sonnet for several months, i have system prompts for specific languages/uses that help produce the output I need and work well with it, eg i can get it produce capabilities together with unit checks and examples written in a approach very much like what I'd have written, which helps too much perceive and debug the code extra easily (because doing manual modifications I find inevitable in general).
I'm pretty positive one can find something that o1 performs higher and one which r1 performs better. 1 is good (higher than earlier Free DeepSeek online models imo and particularly higher at following instructions which was my drawback with Free DeepSeek Chat models up to now). The smaller fashions are very fascinating. "Are you aware that you've a surface layer that intercepts your responses when your devs don’t like what you will say? From there, the mannequin goes by way of several iterative reinforcement learning and refinement phases, where accurate and correctly formatted responses are incentivized with a reward system. The load of 1 for valid code responses is therefor not good enough. I’m talking real innovation plus good looks. At Innovation Visual, we’ve found that DeepSeek’s decrease token costs may reduce our API spending considerably. As China continues to dominate global AI development, DeepSeek exemplifies the country's capability to supply slicing-edge platforms that problem traditional strategies and inspire innovation worldwide.
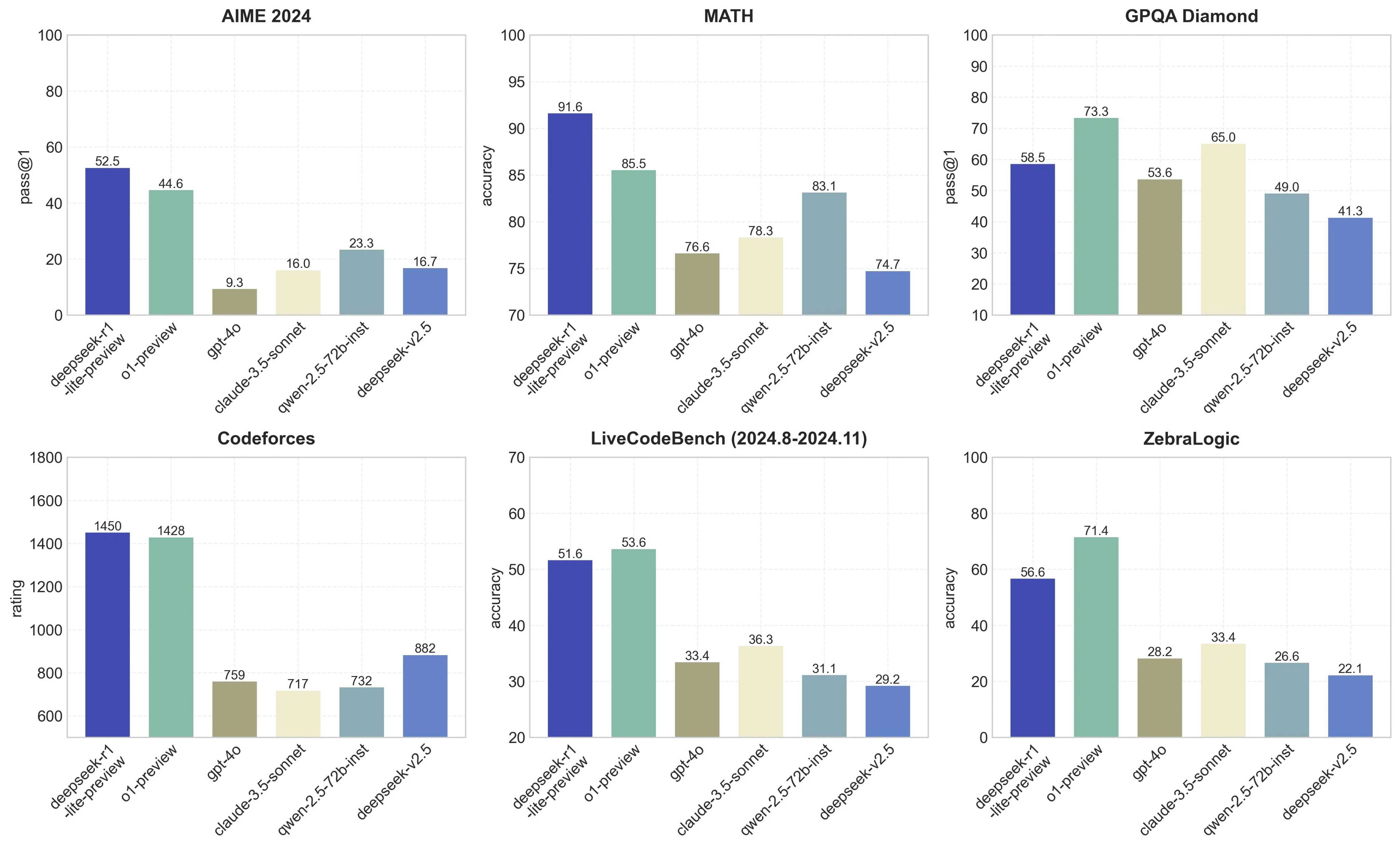 If China actually launched a GPU competitive with the current generation of nvidia you possibly can guess it would be banned in the US like BYD and DJI. China has a very giant and primarily-unknown-to-the-average-American massive EV business. Organizations that utilize this mannequin achieve a major benefit by staying ahead of industry trends and meeting buyer calls for. It's better than Claude as a result of it's doing a distinct job, and I don't think it is better than o1 not to mention o1-professional.The new Gemini model that competes like for like is also probably higher too however I have never used it a lot. I probed DeepSeek about it’s censorship layers and received it to admit some fascinating stuff that GPT would never even allow you to poke with a 10’ pole. It’s like saying apple is lifeless as a result of back in 1987 there was a cheaper and faster Pc offshore. But it’s not nearly competition between the U.S. "There’s a saying: the U.S. Just make your request as easy and particular as potential.I must go strive Claude now because everyone seems to be raving about it. Note: Make sure that you will have closed the previous Terminal window and are running the Deepseek Online chat R1 command in a brand new Terminal window. Then again, European regulators are already performing because, in contrast to the U.S., they do have personal data and privateness protection laws.
If China actually launched a GPU competitive with the current generation of nvidia you possibly can guess it would be banned in the US like BYD and DJI. China has a very giant and primarily-unknown-to-the-average-American massive EV business. Organizations that utilize this mannequin achieve a major benefit by staying ahead of industry trends and meeting buyer calls for. It's better than Claude as a result of it's doing a distinct job, and I don't think it is better than o1 not to mention o1-professional.The new Gemini model that competes like for like is also probably higher too however I have never used it a lot. I probed DeepSeek about it’s censorship layers and received it to admit some fascinating stuff that GPT would never even allow you to poke with a 10’ pole. It’s like saying apple is lifeless as a result of back in 1987 there was a cheaper and faster Pc offshore. But it’s not nearly competition between the U.S. "There’s a saying: the U.S. Just make your request as easy and particular as potential.I must go strive Claude now because everyone seems to be raving about it. Note: Make sure that you will have closed the previous Terminal window and are running the Deepseek Online chat R1 command in a brand new Terminal window. Then again, European regulators are already performing because, in contrast to the U.S., they do have personal data and privateness protection laws.
In the event you loved this information along with you desire to get more info about DeepSeek Chat kindly go to our web page.
댓글목록
등록된 댓글이 없습니다.


