






How To Achieve Deepseek
페이지 정보
작성자 Sol 작성일25-03-17 05:39 조회2회 댓글0건본문
This Python library supplies a lightweight client for seamless communication with the DeepSeek server. Developer Tools: DeepSeek provides complete documentation, tutorials, and a supportive developer neighborhood to help customers get began rapidly. This partnership offers DeepSeek with access to chopping-edge hardware and an open software program stack, optimizing efficiency and scalability. The mannequin works positive within the terminal, but I can’t entry the browser on this digital machine to make use of the Open WebUI. DeepSeek-V2, launched in May 2024, gained significant attention for its strong efficiency and low price, triggering a value battle in the Chinese AI mannequin market. I've just pointed that Vite could not at all times be dependable, based alone expertise, and backed with a GitHub situation with over four hundred likes. Notably, the corporate's hiring practices prioritize technical talents over traditional work experience, leading to a workforce of highly skilled individuals with a recent perspective on AI improvement. Some genres work higher than others, and concrete works better than summary. 8080 hyperlink. Again, the Open WebUI opens, and i can log in, but nothing else works. That means it is used for many of the same duties, though exactly how nicely it works in comparison with its rivals is up for debate.
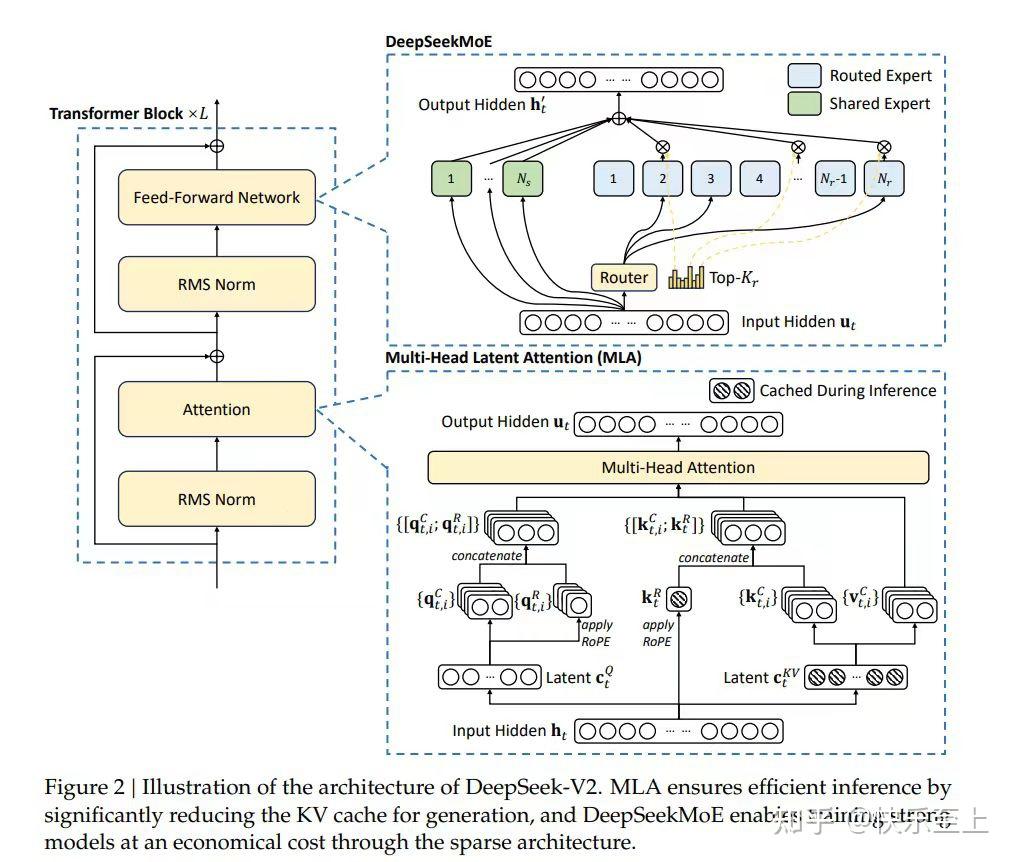 Their technical standard, which goes by the same title, appears to be gaining momentum. DeepSeek's revolutionary methods, value-environment friendly options and optimization methods have had an undeniable impact on the AI landscape. What DeepSeek's emergence truly adjustments is the landscape of model access: Their fashions are freely downloadable by anybody. Beyond the fundamental architecture, we implement two additional strategies to further improve the model capabilities. Basic R&D for AI, aerospace, different areas. Whether you're a newbie or an knowledgeable in AI, DeepSeek R1 empowers you to attain higher efficiency and accuracy in your tasks. This unique funding mannequin has allowed Free DeepSeek r1 to pursue formidable AI initiatives without the stress of exterior traders, enabling it to prioritize lengthy-time period analysis and improvement. In checks resembling programming, this model managed to surpass Llama 3.1 405B, GPT-4o, and Qwen 2.5 72B, though all of those have far fewer parameters, which can influence efficiency and comparisons. DeepSeek additionally affords a spread of distilled models, generally known as DeepSeek-R1-Distill, that are primarily based on well-liked open-weight models like Llama and Qwen, fantastic-tuned on synthetic information generated by R1.
Their technical standard, which goes by the same title, appears to be gaining momentum. DeepSeek's revolutionary methods, value-environment friendly options and optimization methods have had an undeniable impact on the AI landscape. What DeepSeek's emergence truly adjustments is the landscape of model access: Their fashions are freely downloadable by anybody. Beyond the fundamental architecture, we implement two additional strategies to further improve the model capabilities. Basic R&D for AI, aerospace, different areas. Whether you're a newbie or an knowledgeable in AI, DeepSeek R1 empowers you to attain higher efficiency and accuracy in your tasks. This unique funding mannequin has allowed Free DeepSeek r1 to pursue formidable AI initiatives without the stress of exterior traders, enabling it to prioritize lengthy-time period analysis and improvement. In checks resembling programming, this model managed to surpass Llama 3.1 405B, GPT-4o, and Qwen 2.5 72B, though all of those have far fewer parameters, which can influence efficiency and comparisons. DeepSeek additionally affords a spread of distilled models, generally known as DeepSeek-R1-Distill, that are primarily based on well-liked open-weight models like Llama and Qwen, fantastic-tuned on synthetic information generated by R1.
In this course, study to prompt completely different imaginative and prescient fashions like Meta’s Segment Anything Model (SAM), a universal image segmentation mannequin, OWL-ViT, a zero-shot object detection mannequin, and Stable Diffusion 2.0, a broadly used diffusion mannequin. DeepSeek-V3, a 671B parameter model, boasts spectacular performance on numerous benchmarks whereas requiring considerably fewer sources than its peers. DeepSeek-R1’s most significant advantage lies in its explainability and customizability, making it a preferred choice for industries requiring transparency and adaptableness. API Integration: DeepSeek-R1’s APIs enable seamless integration with third-party purposes, enabling businesses to leverage its capabilities with out overhauling their present infrastructure. This method has been significantly effective in growing DeepSeek-R1’s reasoning capabilities. DeepSeek-R1, launched in January 2025, focuses on reasoning duties and challenges OpenAI's o1 mannequin with its superior capabilities. This disruptive pricing technique compelled different major Chinese tech giants, reminiscent of ByteDance, Tencent, Baidu and Alibaba, to lower their AI mannequin costs to stay aggressive.
The Chinese engineers had limited assets, and they had to find creative options." These workarounds seem to have included limiting the variety of calculations that DeepSeek-R1 carries out relative to comparable fashions, and utilizing the chips that had been available to a Chinese firm in ways that maximize their capabilities. The company has additionally solid strategic partnerships to enhance its technological capabilities and market attain. While DeepSeek Chat has achieved exceptional success in a short period, it is important to notice that the company is primarily targeted on research and has no detailed plans for widespread commercialization within the close to future. Healthcare: Optimizing remedy plans and predictive diagnostics. Community Insights: Join the Ollama neighborhood to share experiences and collect tips on optimizing AMD GPU utilization. Finance: Optimizing high-frequency trading algorithms. Finance: Fraud detection and dynamic portfolio optimization. DeepSeek AI Content Detector will not be particularly designed for plagiarism detection. 2. Add context in the Content discipline. It is designed for complicated coding challenges and features a high context size of up to 128K tokens. In the existing course of, we have to read 128 BF16 activation values (the output of the previous computation) from HBM (High Bandwidth Memory) for quantization, and the quantized FP8 values are then written back to HBM, solely to be read once more for MMA.
In case you cherished this information as well as you would want to acquire guidance relating to Deep seek kindly check out the internet site.
댓글목록
등록된 댓글이 없습니다.


